 http://orcid.org/0000-0002-3224-8858
http://orcid.org/0000-0002-3224-8858
by Paul Murrell
http://orcid.org/0000-0002-3224-8858
Version 1: Wednesday 15 April 2020

This document
by Paul
Murrell is licensed under a Creative
Commons Attribution 4.0 International License.
This report describes an update to the R package 'dvir' to add support for the LuaTeX engine. The immediate advantage of this support is the ability to draw typeset text in R with a wider variety of fonts and font features.
The idea behind the 'dvir' package (Murrell, 2020,
Murrell, 2018)
is to be able to
typeset text using Donald Knuth's TeX system (Knuth, 1986),
but render the result in R.
The aim is to render the result using R graphics, but
to obtain identical rendered output compared to the
output
produced by a "normal" TeX renderer like pdflatex.
For example, the following code typesets a simple equation using TeX and renders it in R. The image below the code is text drawn in R using the locations and fonts dictated by TeX.
library(dvir) grid.latex("$x - \\mu$")

The approach used by the 'dvir' package involves generating DVI output from TeX code. This DVI output provides precise information about every individual character of text, including where to draw each character and which font to use. The 'dvir' package reads the DVI information and converts it to 'grid' grobs (graphical objects) for rendering in R.
One of the major limitations of 'dvir' version 0.1-0 was that it was focused just on the TeX Computer Modern fonts. This produces nice mathematical equations, but for normal text can be quite limiting.
The LuaTeX engine (Hagen et al., 2020) differs from the original TeX engine in several important ways:1 it works with Unicode text (so it is easy to specify a very wide range of characters); it provides support for modern font technologies like TrueType and OpenType; and it has an embedded scripting language (called Lua).
The first two of those features mean that, if we can add support for the LuaTeX engine to 'dvir', we will be able to produce a much wider range of typeset text in R graphics.
From a user perspective, there is not much to tell. This is the "ecstacy"; when everything works as planned, we get R graphics output that contains TeX-quality typesetting.
As a simple example,
the following LuaTeX document,
luatex-demo.tex,
contains simple text that
makes use of a Lato Light (non-Computer-Modern) font,
within a paragraph that is 3 inches wide.
\RequirePackage{luatex85} % For more recent versions of LuaTeX
\documentclass[12pt]{standalone}
\usepackage{fontspec}
\setmainfont[Mapping=text-tex]{Lato Light}
\begin{document}
\selectfont
\begin{minipage}{3in}
Some text in Lato Light font.
This sentence just forces some typesetting
(a line break).
\end{minipage}
\end{document}
The following R code runs LuaTeX to typeset the text and generate DVI output, reads the DVI output into R and generates 'grid' grobs, then draws the grobs on an R graphics device.
library(dvir) grid.latex(readLines("luatex-demo.tex"), engine=luatexEngine, preamble="", postamble="")

The new features of this code, compared to the previous version
of 'dvir', are the new arguments to grid.latex:
engine, to specify that we want to use the
LuaTeX engine, rather than the standard TeX engine; and
preamble and postamble, which allow
us to use a complete LuaTeX document as input, rather than
automatically wrapping the input with LaTeX begin/end
code.
The next section goes into the technical detail of getting LuaTeX support in 'dvir'. It is safe to skip ahead to the Examples Section, which contains more elaborate demonstrations of LuaTeX output within R graphics.
This section describes the technical details of adding LuaTeX support. This is the "agony".
This detailed description serves two purposes: when things do not work as planned, these details may provide some suggestions for what went wrong (and perhaps even how to fix it); and this is an important record of the internal design, which is complicated, and will certainly be forgotten if not recorded properly.
The normal way to use LuaTeX is to run
the lualatex program on a LuaTeX document, which produces
a typeset PDF document. However, the 'dvir' package consumes DVI
files, which we can get from LuaTeX by running
the dvilualatex program instead.
The following bash code generates a DVI file,
luatex-demo.dvi,
from the simple LuaTeX document, luatex-demo.tex,
which was shown above.
dvilualatex luatex-demo.tex
The DVI file mostly consists of the usual instructions that adjust
the drawing location,
like right3 and down3,
and the usual instructions to draw a character, like
set_char_83 (an 'S' character).
However,
One major difference between this DVI output from dvilualatex
and the DVI output
from latex is the fnt_def instruction,
which defines a font to use for drawing text, and
in particular its fontname parameter.
readDVI("luatex-demo.dvi")
pre version=2, num=25400000, den=473628672, mag=1000,
comment= LuaTeX output 2020.04.15:2137
bop counters=1 0 0 0 0 0 0 0 0 0, p=-1
push
push
push
push
push
push
push
right3 b=-4736287
down3 a=-4164158
fnt_def_1 fontnum=22, checksum=0, scale=786432, design=655360,
fontname="LatoLight:mode=node;script=latn;language=DFLT;+tlig;"
fnt_num_22
With the TeX engine, and standard Computer Modern fonts, the
fontname is just the name of a font, like cmr12
(meaning Computer Modern Roman at 12 pt size).
The fontname in the DVI above contains a font name,
plus additional information about how the font is being used.
So the first complication for 'dvir' with LuaTeX support
is that we must pull out the information that
we need from the fontname parameter in
fnt_def instructions. For now, we will just
grab the font name
at the start, in this case, LatoLight. We will come
back to some of the other information later.
Having a font name is actually sufficient to draw some text on some graphics devices in R. For example, the Cairo graphics devices can make use of just the font name, as shown below.
library(grid) png("LatoLight.png", type="cairo", width=300, height=50) grid.text("Some text in Lato Light font.", gp=gpar(fontfamily="LatoLight")) dev.off()

However, this does not work for all LuaTeX text
or for all R graphics devices;
as we will see, what we really need is the actual font file that corresponds
to the font that LuaTeX used.
Fortunately, LuaTeX includes a tool called luaotfload-tool
that can help us.
luaotfload-tool --find=LatoLight
luaotfload | resolve : Font "LatoLight" found! luaotfload | resolve : Resolved file name "/usr/share/fonts/truetype/lato/Lato-Light.ttf"
This font file will allow us to find out much more about the font than just its name and that will help us to use the font for more complex text.
The simple LuaTeX example above only makes use of ASCII characters.
This means that all of the DVI instructions to draw a character in
that example are of
the form set_char_n. The n
gives the ASCII encoding
for the character: e.g.,
set_char_83 means a capital 'S' character.
However, LuaTeX documents support Unicode text, so we can have, for example, text with accents or diacritics, like the c-cedilla, ç, in the document below.
\RequirePackage{luatex85}
\documentclass{standalone}
\usepackage{fontspec}
\setmainfont[Mapping=text-tex]{Lato Light}
\begin{document}
\selectfont
Du texte français en police Lato Light.
\end{document}
We can generate a DVI file with dvilualatex as before ...
dvilualatex luatex-demo-unicode.tex
... and the start of this DVI file is very much like the previous one (just with the 'D' from "Du" instead of the 'S' from "Some").
readDVI("luatex-demo-unicode.dvi")
pre version=2, num=25400000, den=473628672, mag=1000,
comment= LuaTeX output 2020.04.15:2137
bop counters=1 0 0 0 0 0 0 0 0 0, p=-1
push
push
push
push
push
right3 b=-4736287
down3 a=-4259513
fnt_def_1 fontnum=21, checksum=0, scale=655360, design=655360,
fontname="LatoLight:mode=node;script=latn;language=DFLT;+tlig;"
fnt_num_21
set_char_68 'D'
right2 b=-6225
However, if we look at the DVI information for the
text around the word "français", we see a set_char1
instruction (a single byte character outside the range 0-127),
with a parameter e7.
right2 b=-6553 set_char_97 'a' set_char_110 'n' set_char1 e7 set_char_97 'a' set_char_105 'i' set_char_115 's'
This shows how LuaTeX expresses Unicode text (within the range 128-255).
The value e7 is a UTF16BE encoding for the Unicode character
"LATIN SMALL LETTER C WITH CEDILLA" (the full encoding is 00e7,
but the 00 is dropped to allow the DVI to just record
a single byte).
The next example demonstrates a full 2-byte UTF16BE encoding. This time we have a LuaTeX document that contains the character sequence "fi" (in the word "fine").
\RequirePackage{luatex85}
\documentclass{standalone}
\usepackage{fontspec}
\setmainfont[Mapping=text-tex]{Lato Light}
\begin{document}
\selectfont
Some fine text in Lato Light font.
\end{document}
dvilualatex luatex-demo-flig.tex
If we look at the DVI information around the word "fine",
we see two interesting points: the "fi" has been reduced down to
a single character; and that character is expressed as a
set_char2 instruction (a 2-byte character),
with parameter fb 01.
readDVI("luatex-demo-flig.dvi")
set_char_109 'm' set_char_101 'e' right3 b=177930 set_char2 fb 01 set_char_110 'n' set_char_101 'e' right3 b=177930
What has happened is that LuaTeX has replaced
the two characters 'f' followed by 'i' with a single ligature
character that combines the 'f' and the 'i' (to deal with the fact that
the top of the 'f' and the dot on the 'i' may interfere with each
other). The value fb 01
is the UTF16BE encoding for the Unicode character 'LATIN SMALL
LIGATURE FI'.
So another part of supporting LuaTeX in 'dvir' is being able to
convert these UTF16BE encodings into something that R understands.
The 'dvir' package uses the iconv function to
perform this conversion.
iconv(list(as.raw(as.hexmode(c("00", "e7")))), from="UTF16BE", to="UTF-8")
[1] "ç"
iconv(list(as.raw(as.hexmode(c("fb", "01")))), from="UTF16BE", to="UTF-8")
[1] "fi"
These UTF-8 character values are sufficient for drawing on Cairo-based R graphics devices at least, because the Cairo graphics device handles UTF-8 text.
The next example increases the complexity significantly. In this LuaTeX document, we have the character sequence "ti" (in the word "timely").
\RequirePackage{luatex85}
\documentclass{standalone}
\usepackage{fontspec}
\setmainfont[Mapping=text-tex]{Lato Light}
\begin{document}
\selectfont
Some timely text in Lato Light font.
\end{document}
If we look at the DVI information around the word "timely",
we again see that the "ti" has been reduced down to
a single character (a ligature) and this time we have a
set_char3 instruction (a 3-byte character),
with parameter 0f 02 d5.
dvilualatex luatex-demo-tlig.tex
readDVI("luatex-demo-tlig.dvi")
set_char_109 'm' set_char_101 'e' right3 b=177930 set_char3 0f 02 d5 set_char_109 'm' set_char_101 'e' set_char_108 'l'
Similar to the "fi" example, the "ti" character sequence
has been reduced to a single ligature. However, this example
is more complicated because the "ti" ligature does not exist
in Unicode. The bytes 0f 02 d5 do not represent
an encoding for a Unicode character.
This lack of Unicode representation
presents two problems: how do we map the 0f 02 d5
value to an R character value? and how do we express that character
to an R graphics device?
The fact that LuaTeX has generated DVI information with
3 bytes (with 0f as the
first byte) is an indication that the character we need to draw
is not a Unicode character.
The remaining two bytes, in this case 02 d5, are an
integer index, in this case 725, that means we should use the 725th
non-Unicode character in the current font. To be more accurate, it means
that we should use the 725th
non-Unicode glyph in the current font.
If the expression "the 725th non-Unicode glyph in the current font" seems confusing to you, you are not alone. We need to unpack it a little to understand what is going on.
First of all, a character is a concept, while a glyph is a concrete symbol representing that concept. The character 'A' is represented by different glyphs in different fonts; the 'A' in a serif font like Times New Roman looks different to the 'A' in a monospace font like Courier.
A font is a collection of glyphs, most of which are shapes representing
characters. A font also contains (or refers to) an encoding,
which maps each glyph to a numeric value. For example, the Lato Light
font contains a glyph representing the character 'S' and an
encoding that maps 'S' glyph to the number 83. It also
contains a glyph representing the "fi" ligature and an encoding
that maps the "fi" ligature glyph to the number 64257 (fb 01
in hexadecimal form).
Normally, when we draw text, we specify the characters to draw, the font to use, and (often implicitly) an encoding. The encoding maps the characters to the correct glyph within the font.
If we ignore the encoding, a font consists of just a collection of
glyphs, from 1 to the number of glyphs in the font. We do not
usually access fonts this way, but the TTX tool (part of
the fonttools project; van Rossum et al., 2020)
can extract this information for us.
The following code extracts the names and order of the
glyphs (the GlyphOrder table) from the font file
Lato-Light.ttf to a new file called
Lato-Light-GlyphOrder.ttx.
cp /usr/share/fonts/truetype/lato/Lato-Light.ttf Fonts/
ttx -t GlyphOrder -o Fonts/Lato-Light-GlyphOrder.ttx Fonts/Lato-Light.ttf
Looking at the start of the
Lato-Light-GlyphOrder.ttx file,
we can see that the glyph for 'A' is the fourth glyph in the font.
head Fonts/Lato-Light-GlyphOrder.ttx
<?xml version="1.0" encoding="UTF-8"?>
<ttFont sfntVersion="\x00\x01\x00\x00" ttLibVersion="3.0">
<GlyphOrder>
<!-- The 'id' attribute is only for humans; it is ignored when parsed. -->
<GlyphID id="0" name=".notdef"/>
<GlyphID id="1" name="uni0000"/>
<GlyphID id="2" name="uni00A0"/>
<GlyphID id="3" name="A"/>
<GlyphID id="4" name="AE"/>
The glyph for 'S' is the 26th glyph (NOT the 83rd).
grep -C 3 '"S"' Fonts/Lato-Light-GlyphOrder.ttx
<GlyphID id="22" name="P"/>
<GlyphID id="23" name="Q"/>
<GlyphID id="24" name="R"/>
<GlyphID id="25" name="S"/>
<GlyphID id="26" name="T"/>
<GlyphID id="27" name="U"/>
<GlyphID id="28" name="V"/>
The "fi" ligature glyph is the 42nd glyph (NOT the 64257th).
grep -C 3 FB01 Fonts/Lato-Light-GlyphOrder.ttx
<GlyphID id="38" name="d"/>
<GlyphID id="39" name="e"/>
<GlyphID id="40" name="f"/>
<GlyphID id="41" name="uniFB01"/>
<GlyphID id="42" name="uniFB02"/>
<GlyphID id="43" name="g"/>
<GlyphID id="44" name="h"/>
What we can also see from this TTX output is that each glyph has
a name. In some cases, the name is quite familiar, e.g., "A"
or "S" and in other cases, the name is less familiar, but still
useful, because it points us to the Unicode code point for the glyph, e.g.,
"uniFB01" for the "fi" ligature. But there is a third
set of glyph names that are totally inscrutable. These names are of
the form "glyphi, where i simply reflects the
rank of the glyph within the font.
grep -C 3 glyph Fonts/Lato-Light-GlyphOrder.ttx | head -7
<GlyphID id="235" name="Tbar"/>
<GlyphID id="236" name="Uogonek"/>
<GlyphID id="237" name="aogonek"/>
<GlyphID id="238" name="glyph00238"/>
<GlyphID id="239" name="glyph00239"/>
<GlyphID id="240" name="glyph00240"/>
<GlyphID id="241" name="glyph00241"/>
If we treat glyphs with an inscrutable name as non-Unicode glyphs, we can find the 725th non-Unicode glyph within the font. The "ti" glyph is the 2472nd glyph in the font. (We have two off-by-one adjustments here, at least one of which is just accounting for zero-based versus one-based indexing.)
grep glyph Fonts/Lato-Light-GlyphOrder.ttx | sed '724q;d'
<GlyphID id="2471" name="glyph02471"/>
The image below shows glyph number 2471 from Lato-Light.ttf
(viewed with FontForge; Williams and The FontForge Project contributors, 2020).
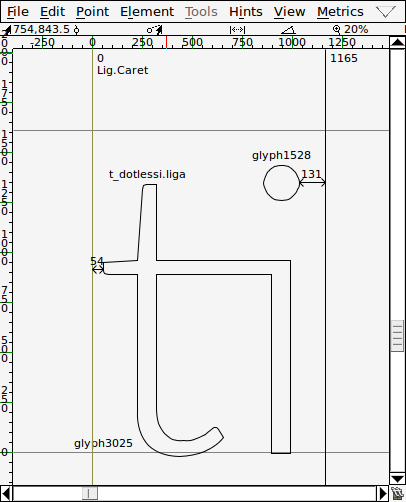
This gives us the name of the glyph within the font, in this case
glyph02471.
Having established which glyph within the font LuaTeX is referring to, we are still left with the problem of actually accessing that glyph from within R. When we draw text in R, what gets sent to an R graphics device is a character value, not a glyph number. We need a way to specify a character value that selects the glyph that we want.
The approach taken by 'dvir' to solve this problem involves creating a new mini-font that just contains the non-Unicode glyph (with an encoding that maps the glyph to an ASCII character). This requires several steps.
We can extract a single glyph from a font using
pyftsubset from fonttools.
The following code extracts glyph 2471 from Lato-Light.ttf
and saves it in a new font called Lato-Light-glyph02471.ttf.
The name-IDs argument will be explained later.
pyftsubset Fonts/Lato-Light.ttf --gids=2471 --output-file=Fonts/Lato-Light-glyph02471.ttf --name-IDs='*'
This new font contains no encoding, so the glyph within it is still inaccessible. Furthermore, the new font has exactly the same name as the old font, which will make it difficult to specify this new font separately from the original font. To rename the font and add the encoding, we can convert the font to an XML format, with TTX, modify the font name (edit the name table), insert an encoding (a cmap table), and then convert back to TrueType format.
The following code converts our new mini TrueType font to XML.
ttx Fonts/Lato-Light-glyph02471.ttf
In order to insert a cmap table, we need to know the name of the glyph in the new font. Unfortunately, this is not the same as the name of the glyph in the original font. The following code shows the GlyphOrder table for the new font.
library(xml2) ttx <- read_xml("Fonts/Lato-Light-glyph02471.ttx") xml_find_first(ttx, "//GlyphOrder")
{xml_node}
<GlyphOrder>
[1] <GlyphID id="0" name=".notdef"/>
[2] <GlyphID id="1" name="glyph00001"/>
[3] <GlyphID id="2" name="glyph00002"/>
[4] <GlyphID id="3" name="glyph00003"/>
[5] <GlyphID id="4" name="glyph00004"/>
There are a couple of surprises: there is a .notdef
glyph that we did not ask for (we always get this); none of
the glyphs are called glyph02417; and there
are four glyphs besides .notdef,
not just the one we asked for.
This has happened because the glyph that we want is actually composed from several other glyphs in the original font. We can see this by looking at the glyf table of the original font.
ttx -t glyf -o Fonts/Lato-Light-glyf.ttx Fonts/Lato-Light.ttf
ttx <- read_xml("Fonts/Lato-Light-glyf.ttx") xml_find_first(ttx, "//TTGlyph[@name = 'glyph02471']")
{xml_node}
<TTGlyph name="glyph02471" xMin="54" yMin="-16" xMax="1034" yMax="1439">
[1] <component glyphName="glyph03025" x="54" y="0" flags="0x0"/>
[2] <component glyphName="glyph00294" x="0" y="0" flags="0x0"/>
[3] <component glyphName="glyph01528" x="545" y="0" flags="0x0"/>
[4] <instructions>\n <assembly>\n PUSH[ ]\t/* 6 values pushed */\n 53 43 35 21 ...
When there are no component elements, the glyph we
want will be the only glyph in the subsetted font, so we can just
use glyph00001 from the new font. But when the
glyph we want is composed from other glyphs, the subsetted font
will contain several glyphs, in this case four (the glyph we
want plus the three that it was composed from).
There is now the problem of figuring out which of these four glyphs is the glyph that we want. To do this, we need to look at the names of the four glyphs and find out what order they are arranged in within the original font (and assume that that order is retained in the subsetted font).
In this case, the answer is quite simple because the names of the
glyphs tell us their order; glyph02471 is the third
out of these four glyphs (2471 comes after 294 and 1528, but before
3025).
In general, we can match the names of the glyphs from the glyf table to glyph names in the GlyphOrder table to determine their order.
In summary, the glyph that we want in the subsetted font has the name
glyph00003.
The R code below inserts a cmap table that
maps the number 65 (hex 41, ASCII for character "A") to
glyph00003 in the new font.
ttx <- read_xml("Fonts/Lato-Light-glyph02471.ttx") cmap <- xml_find_first(ttx, "//cmap") cmapTable <- read_xml('<cmap_format_4 platformID="0" platEncID="3" language="0"/>') xml_add_child(cmapTable, "map", code="0x41", name="glyph00003") xml_add_child(cmap, cmapTable)
<cmap>
<tableVersion version="0"/>
<cmap_format_4 platformID="0" platEncID="3" language="0">
<map code="0x41" name="glyph00003"/>
</cmap_format_4>
</cmap>
A similar approach can be used to give the new font a different name,
by editing the name table within the XML.
The name-IDs argument that we saw earlier in the
call to pyftsubset exports the existing font name,
so in this step we are just modifying the name table rather than
creating a new one from scratch.
The following code changes the "Font Family" name; in the
full code, we also modify the "Full" font name, which includes
possible modifiers like "Bold" or "Light", and the PostScript
name for the font.
name <- xml_find_first(ttx, "//name") familyname <- xml_find_first(name, "namerecord[@nameID = '1']") xml_set_text(familyname, "custom_font_1")
Finally, we write the modified XML to a new file and reverse the conversion from XML back to a TrueType font.
write_xml(ttx, "Fonts/Lato-Light-glyph02471-enc.ttx")
ttx Fonts/Lato-Light-glyph02471-enc.ttx
We can use fc-scan to see that the new font has
a different name from the original font.
fc-scan Fonts/Lato-Light.ttf | grep family:
family: "Lato"(s) "Lato Light"(s)
fc-scan Fonts/Lato-Light-glyph02471-enc.ttf | grep family:
family: "custom_font_1"(s)
The last step (for Cairo graphics devices in R) is to make sure that Fontconfig (Packard, 2020, Packard, 2002) can see the new font. This can be done by creating a configuration file, as shown below, and placing that in a directory that Fontconfig can see.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig>
<!--include directory containing custom font (within docker container) -->
<dir>/home/work/Fonts/</dir>
</fontconfig>
file.copy("99-custom-font.conf", "~/.fonts.conf.d/", overwrite=TRUE) file.copy("99-custom-font.conf", "~/fontconfig/conf.d/", overwrite=TRUE)
We also need to force FontConfig to look at this new configuration, which we can do using the 'systemfonts' package (Pedersen et al., 2020).
systemfonts::reset_font_cache()
From R, we can now select this font and draw the "ti" ligature by asking the font for an 'A' character.
png("LatoLight-ti_lig.png", type="cairo", width=200, height=50) grid.text("A", gp=gpar(fontfamily="custom_font_1", cex=3)) dev.off()
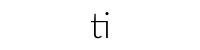
Because R graphics can only use one font for drawing a piece of text, we have to draw this special character as an individual piece of text. However, this is how 'dvir' works generally, because the DVI output that it works from contains information about every individual character, so this is not a problem (or at least not a new problem).
The DVI output that 'dvir' is working from contains two types of adjustments to the drawing location: explicit moves, e.g., the space between words and kerning adjustments between letters; and implicit moves based on instructions to draw a character. The latter adjusts the drawing location so that we can just draw the next character alongside this character (if this is not the end of a word and there is no kerning).
We can see this in the DVI from our very first example.
The set_char_83 instruction draws an 'S',
which implicitly adjusts the current location to
just after the 'S'.
The right2 makes an explicit kerning adjustment.
We then draw an 'o', which implicitly adjusts the location, and then
an 'm', which implicitly adjusts the location.
fnt_def_1 fontnum=22, checksum=0, scale=786432, design=655360,
fontname="LatoLight:mode=node;script=latn;language=DFLT;+tlig;"
fnt_num_22
set_char_83 'S'
right2 b=-4718
set_char_111 'o'
set_char_109 'm'
In order to make the implicit adjustments, we must figure out the width of a character (so that we can shift the current location to just after the character).
R provides functions to calculate this font metric information,
e.g., grid::stringWidth and
grid::grobWidth, but on some
Cairo graphics devices
the information is not accurate enough (for drawing individual characters).
The following code demonstrates this problem. We create a 'grid' text grob containing the letter 'o' with the Lato Light font. We open a PDF graphics device (and load the 'extrafont' package so that PDF graphics devices can use system fonts like Lato Light) and calculate the width of the letter "o". ("bigpts" are PostScript's 1/72in, as compared to TeX "pts", which are 1/72.27in.)
tg <- textGrob("o", gp=gpar(fontfamily="Lato Light")) library(extrafont)
pdf("o-metric.pdf") grid.draw(tg) convertWidth(grobWidth(tg), "bigpts")
[1] 6.696bigpts
dev.off()
Now we do the same thing on a Cario PDF graphics device, but we get a different width (because the Cairo graphics devices only get metric values to the nearest "pixel").
cairo_pdf("o-metric-cairo.pdf") grid.draw(tg) convertWidth(grobWidth(tg), "bigpts")
[1] 7.00000000000001bigpts
dev.off()
What this means is that, in order to position text exactly the same as LuaTeX has described in its DVI output, we cannot use the Cairo graphics metric information.
Two solutions to this problem have been implemented. In the previous version of 'dvir', using the TeX engine, a PDF graphics device is used to calculate character metrics even on Cairo PDF devices. In this new version of 'dvir', when we use the LuaTeX engine and a non-Computer Modern font, character metrics are calculated by extracting the information from the font file directly. This is because using a PDF graphics device to calculate character metrics would be difficult because we are trying to support a very wide range of character input (Unicode).
Again, the first step is to use TTX to extract metric information to an XML format. This time we are extracting the hmtx (horizontal metrics) table.
ttx -t hmtx -o Fonts/Lato-Light-hmtx.ttx Fonts/Lato-Light.ttf
We can see that the resulting file contains width information for each glyph in the font.
head Fonts/Lato-Light-hmtx.ttx
<?xml version="1.0" encoding="UTF-8"?>
<ttFont sfntVersion="\x00\x01\x00\x00" ttLibVersion="3.0">
<hmtx>
<mtx name=".notdef" width="1025" lsb="47"/>
<mtx name="A" width="1311" lsb="26"/>
<mtx name="AE" width="1855" lsb="10"/>
<mtx name="AEacute" width="1855" lsb="10"/>
<mtx name="Aacute" width="1311" lsb="26"/>
<mtx name="Abreve" width="1311" lsb="26"/>
One complication is determining the scale of those widths.
This requires looking at the head table from the font,
in particular the unitsPerEm information.
ttx -t head -o Fonts/Lato-Light-head.ttx Fonts/Lato-Light.ttf
grep -C 3 unitsPerEm Fonts/Lato-Light-head.ttx
<checkSumAdjustment value="0x932003c8"/>
<magicNumber value="0x5f0f3cf5"/>
<flags value="00000000 00011011"/>
<unitsPerEm value="2000"/>
<created value="Fri Jan 22 17:43:08 2010"/>
<modified value="Thu Feb 27 03:42:25 2014"/>
<xMin value="-959"/>
The character width, in points, is the font size (in whole points) multiplied by the width metric (scaled to 1000 unitsPerEm and then scaled to a unit square). The following code and output shows how we can obtain the correct width of a "o" character.
grep -C 3 '"o"' Fonts/Lato-Light-hmtx.ttx
<mtx name="ntilde" width="1100" lsb="164"/>
<mtx name="nu" width="1007" lsb="39"/>
<mtx name="numbersign" width="1160" lsb="80"/>
<mtx name="o" width="1116" lsb="104"/>
<mtx name="oacute" width="1116" lsb="104"/>
<mtx name="obreve" width="1116" lsb="104"/>
<mtx name="ocircumflex" width="1116" lsb="104"/>
12 * 1116/(2000/1000)/1000
[1] 6.696
All that remains is to locate the correct character metric.
We can see from Lato-Light-hmtx.ttx that this requires
finding the correct glyph name for the character.
The fontTools
documentation describes how the glyph names in the TTX files are determined
and 'dvir' attempts to mimic that in order
to obtain an appropriate glyph name. For example, an 'o' character
will be a set_char_111 (6F in hex) in DVI and we can use the
Adobe Glyph List
to map 006F to the glyph name "o".
Because the glyphs names in TTX output do not always use the
Adobe Glyph List names, we also generate glyph names of the form
uniXXXX, where XXXX is the relevant
UTF8 code point. Furthermore, in some fonts, a single glyph
may be used for multiple characters and,
in that case, the font may not contain a
glyph with the expected name. To help with this case, we also
generate a glyph name from the Unicode cmap table within a font
(if it exists).
For example, a "-" (dash or hyphen or "hyphen-minus") character
will be a set_char_45 (2D in hex) in DVI.
The Adobe Glyph List maps 002D to the name "hyphen",
so that is the first name that we will try. Unfortunately,
a font may not contain a glyph named "hyphen".
grep -c -i hyphen Fonts/Lato-Light-hmtx.ttx
0
We also try the glyph name uni002D, but in this case,
there is no glyph of that name either.
grep -c -i 002D Fonts/Lato-Light-hmtx.ttx
0
Finally, we look in the Unicode cmap table to see which glyph
is being used for the code point 002D.
ttx -t cmap -o Fonts/Lato-Light-cmap.ttx Fonts/Lato-Light.ttf
Dumping "Fonts/Lato-Light.ttf" to "Fonts/Lato-Light-cmap.ttx"... Dumping 'cmap' table...
xmllint --xpath "//cmap_format_4[@platformID='0']/map[@code='0x2d']" Fonts/Lato-Light-cmap.ttx
<map code="0x2d" name="uni00AD"/>
This tells us that the glyph uni00AD (a "soft hyphen")
is being used for code point 002D ("hyphen-minus"),
so we look for that name as well. And there is metric information
for that glyph.
grep -i 00AD Fonts/Lato-Light-hmtx.ttx
<mtx name="uni00AD" width="740" lsb="138"/>
Armed with all of that information, we can now consume DVI output
from LuaTeX and draw the result in R. Of course, the 'dvi'
package wraps all of that detail within a more convenient interface,
e.g., the grid.latex function. The next section
provides more demonstrations of the use of that interface.
As demonstrated by the simple example in the Section Adding LuaTeX support to 'dvir', one benefit of adding LuaTeX support to the 'dvir' package is that we can easily make use of fonts beyond the Computer Modern family. To be clear, this is extending the range of fonts that we can use to draw text with TeX-quality typesetting in R graphics; it was already possible to draw a normal R character value with a wide range of fonts, but that sort of text is not typeset with any sophistication.
The next example makes it clearer that we are typesetting text (using LuaTeX) rather than just relying on R's text-drawing facilities. The LuaTeX document below describes text with several interesting features: the main font is Economica (a Google font that has been downloaded, in TrueType format, to a local file); the first line of text is bold; and the remaining text is typeset in a paragraph with steadily decreasing line length.
\RequirePackage{luatex85}
\documentclass{standalone}
\usepackage{fontspec}
\setmainfont{Economica-regular.ttf}[
BoldFont=Economica-bold.ttf,
ItalicFont=Economica-italic.ttf,
BoldItalicFont=Economica-bolditalic.ttf
]
\begin{document}
\fontsize{14}{16}\selectfont
\begin{minipage}{3in}
{\bf Longley's Economic Regression Data:}
\parshape 5
0pt .7\textwidth
0pt .6\textwidth
0pt .5\textwidth
0pt .4\textwidth
0pt .3\textwidth
A macroeconomic data set which provides a well-known example for a
highly collinear regression.
\end{minipage}
\end{document}
The following code combines that typeset text with an R plot (in R).
First, we draw a simple barplot.
Then we call grid.latex
from the 'dvir' package to typeset the text using LuaTeX and
draw the result within the R plot. Some of the clues that tell
us this is typeset text rather than just R drawing a character value
are the stretching of space between words (e.g., on the first line
of non-bold text) and the hyphenation of some words at line breaks.
barplot(GNP ~ Year, data = longley) latex <- readLines("luatex-float.tex") grid.latex(latex, engine=luatexEngine, preamble="", postamble="", x=unit(1, "npc") - unit(5, "in"), y=unit(1, "npc") - unit(1, "in"), just=c("left", "top"))

The next example demonstrates that, in addition to providing an easy way to select a wider range of fonts, adding LuaTeX support to 'dvir' provides access to LuaTeX's sophisticated font handling features. For example, the following LuaTeX document typesets the same piece of text twice: once with the standard Computer Modern font (actually LuaTeX selects the Latin Modern font, but that is very similar to Computer Modern) and once using the Lato Light font with so-called "discretionary" ligatures (ch, ct, ck) and "old-style" numerals (with varying heights and alignments) selected. These font features are not accessible from R's standard text drawing functions.
\RequirePackage{luatex85}
\documentclass{standalone}
\usepackage{fontspec}
\begin{document}
\fontsize{14}{16}\selectfont
\begin{minipage}{3in}
characteristick 12345\\
\fontspec{Lato Light}[Ligatures=Discretionary,Numbers=OldStyle]
characteristick 12345
\end{minipage}
\end{document}
The following code draws the resulting typeset text in R.
latex <- readLines("luatex-features.tex") grid.latex(latex, engine=luatexEngine, preamble="", postamble="")

The final example comes from Figure 4.1 in Thomas Rahlf's "Data Visualisation with R" (Rahlf, 2017). In the original example in the book, an R plot is included within a LaTeX document with the LaTeX text overlaid on the plot using the LaTeX package 'overpic' (i.e., using LaTeX to combine the plot and text). The example below demonstrates an R-driven alternative, where we overlay text on a plot using R to combine the two.
The R code for the plot is provided in a separate file (downloaded from the book web site). The result of running the code is shown below; note the use of the Lato Light font for labelling.

The LaTeX code that describes the text to overlay on the plot is shown below (also taken from the book web site). Important points to note here are the use of Lato Light font and the fact that the text is typeset in a two-column format.
\RequirePackage{luatex85}
\documentclass{standalone}
\usepackage{multicol}
\setlength{\columnsep}{1cm}
\usepackage{fontspec}
\setmainfont[Mapping=text-tex]{Lato Light}
\begin{document}
\pagestyle{empty}
\fontsize{12pt}{17pt}\selectfont
\begin{minipage}[t]{16.25cm}
\begin{multicols}{2}
From a general and economic policy perspective, the entire period from
1820 to 1930 can be described as a relatively liberal period. With the
"Pacific War", as a result of which the nitrate mines were awarded to
Chile, the economy experienced a profound upswing. The period from
1940 to 1973 is generally seen as a phase in which the government
increasingly intervened in the economy and Chile was isolated
internationally. During the Allende regime (1971 to 1973), this policy
was exaggerated and the economy practically became a central
economy. The military regime (1973 to 1990) - despite numerous
violations of human rights - ensured liberalization of trade and
finance.
\end{multicols}
\end{minipage}
\end{document}
The following code performs the overlay of the text on the plot
using 'dvir'. A little bit of set up is necessary to convert
the original 'graphics' plot to a 'grid' plot (using the
'gridGraphics' package; Murrell and Wen, 2020,
Murrell, 2015),
but the drawing of the text requires
just a single function call to grid.latex.
## Draw main plot source("rahlf-plot.R") latex <- readLines("rahlf-text.tex") gridGraphics::grid.echo() downViewport("graphics-plot-1") ## Add LuaTeX typeset text grid.latex(latex, preamble="", postamble="", engine=luatexEngine, x=unit(1, "cm"), y=unit(1, "npc") - unit(1, "cm"), just=c("left", "top"))

One important thing to note is how the text is positioned relative
to the plot; the top-left of the text is exactly 1cm in from the top-left
corner of the plot region. This very explicit and precise
positioning is in contrast to the LaTeX-driven approach of
the original figure in Rahlf's book. The relevant piece of LaTeX
code that performs the positioning in that case is shown below;
the position (60,128), which dictates the location of
the text on the plot, is 6cm in and 12.8 cm up
from the bottom-left of the entire plot
image; it is not relative to the plot region within the plot.
That is very much a trial-and-error location compared
to the deliberate and expressive positioning that is possible
when combining the text with the plot in R.
\begin{overpic}[scale=1,unit=1mm]{timeseries_areas_below_inc.pdf}
\put(60,128)
The 'dvir' package provides a way to include typeset text within an R plot. The new version of the 'dvir' package, which adds support for the LuaTeX engine, provides access to a much wider range of typeset text, including a wider range of fonts.
On the downside, many limitations of the original package remain. Drawing is very slow and support is only limited to specific R graphics devices (so far). Even worse, LuaTeX support is only offered for Cairo-based graphics devices (at this point). Furthermore, the package has only been tested (and is only expected to run) on Linux; it only makes use of Linux-based font-related tools like FontConfig and fonttools. This package remains a proof-of-concept.
On the other hand, for anyone working on Linux and/or prepared to make use of Docker it might provide a way to produce graphical results that are not obtainable any other way.
When the package does not produce the desired result,
the most likely source of problems is fonts.
LuaTeX may make use of system fonts or TeX fonts.
For system fonts, 'dvir' uses 'extrafont' to specify the
font to R graphics.
If a font is not found,
try running extrafont::font_import first to make sure that
'extrafont' knows about all of your fonts and/or install additional
font packages on your system.
The extrafont::font_import function
can also be used to make sure that 'dvir' knows about local fonts that are
not installed on the system (like the Economica font used in one
example in this report).
The examples and discussion in this document relate to version
0.2-0 of the 'dvir' package and
the development version
of the 'systemfonts' package (for the reset_font_cache
function).
This report was generated within a Docker container (see the Resources section below).
luatex-demo.tex,
luatex-demo-unicode.tex,
luatex-demo-flig.tex,
luatex-demo-tlig.tex,
luatex-float.tex,
and
luatex-features.tex.
The files for Thomas Rahlf's figure are:
rahlf-plot.R for the plot and
rahlf-text.tex for the text.
The example FontConfig configuration file is:
99-custom-font.conf.
Murrell, P. (2020). "The Agony and the Ecstacy: Adding LuaTeX support to 'dvir'" Technical Report 2020-02, Department of Statistics, The University of Auckland. [ bib | DOI | http ]
1
Some terminology:
A TeX document consists of a combination of text to typeset
and (low-level) TeX commands that describe the typesetting.
A LaTeX document consists of a combination of text to
typeset and (higher-level) LaTeX commands the describe the typesetting.
A LuaTeX document consists of a combination of text
to typeset and (higher-level) LaTeX commands that describe the typesetting
and (optionally) Lua code to do crazy things.
A TeX document
is processed by a TeX engine, an executable program,
to produce a typeset document, in some format.
Most TeX engines provide a LaTeX variant that processes LaTeX documents.
The original TeX engine provides a latex program to
typeset a LaTeX document in DVI format.
The pdfTeX engine provides a pdflatex program to
typeset a LaTeX document in PDF format.
The LuaTeX engine provides a lualatex program to
typeset a LuaTeX document in PDF format and a
dvilualatex program to
typeset a LuaTeX document in DVI format.
This document
by Paul
Murrell is licensed under a Creative
Commons Attribution 4.0 International License.