 http://orcid.org/0000-0002-3224-8858
http://orcid.org/0000-0002-3224-8858
by Paul Murrell
http://orcid.org/0000-0002-3224-8858
Version 1: Thursday 01 March 2018

This document
by Paul
Murrell is licensed under a Creative
Commons Attribution 4.0 International License.
This report describes different methods for correctly rendering macrons in Māori text within R plots. The topics covered will also have relevance to rendering other special characters in R graphics and possibly to rendering macrons in other software.
Te reo Māori (the Māori language) is an official language of New Zealand. In written Māori, the pronunciation of vowels can be modified by placing a macron above the vowel. A macron indicates a "long vowel" and can significantly alter the meaning of a word, e.g., keke vs kēkē (cake vs armpit).
The macron is the only accent required for written Māori and the accent can only be applied to vowels, so the full set of accented characters are:
| lower case a, with macron | ā | upper case A, with macron | Ā | |
| lower case e, with macron | ē | upper case E, with macron | Ē | |
| lower case i, with macron | ī | upper case I, with macron | Ī | |
| lower case o, with macron | ō | upper case O, with macron | Ō | |
| lower case u, with macron | ū | upper case U, with macron | Ū |
This document focuses on the problem of accurately producing these accented characters within a plot in R graphics (R Core Team, 2017). We will demonstrate some of the problems and then provide an explanation of why the problems arise and how to solve them. Readers who just want an answer might like to skip straight to the Summary.
There is a surprising amount of complexity involved in correctly producing any sort of text; we usually do not see this complexity simply because producing text mostly just works.
In this section, we will look at a few simple demonstrations of how things can easily go wrong when we try to produce a macron-accented character in R. In this document, we are only interested in using macron-accented characters within R character vectors (not within R symbol names).
To provide us with an example, we will create a plot using a data set from Statistics New Zealand that contains the percentage of the Māori population who speak te reo Māori (based on the last three censuses).
speakers <- read.csv("StatsNZ/maori-language-speakers.csv", header=FALSE, col.names=c("Census", "Speakers", "Total", "Percent")) speakers
Census Speakers Total Percent 1 2001 130,485 518,727 25.2 2 2006 131,610 554,355 23.7 3 2013 125,352 588,267 21.3
We want to produce a simple bar plot of these data, with a title that includes the word "Māori", appropriately accented.
Our first attempt involves cutting-and-pasting an "ā" character from a Word document (that already contains the character ā) into the Rgui console. Unless otherwise specified, we will be working on Windows.
barplot(speakers$Percent, names.arg=speakers$Census, ylab="Percent", main="Speakers of te reo Māori in the Māori ethnic group", family="Microsoft New Tai Lue")
Unfortunately, even though we can see the "ā" character in the console, it mysteriously becomes a normal "a" in the plot.
The problem here is partly to do with how we type a macron-accented character in R. It is unlikely that we have an "ā" key on our keyboard, so we have to find some other way to input that character (like cutting and pasting from another program or document).
The problem is also to do with encodings (how characters are stored in software). Different operating systems and different applications can use different encodings and any mismatch between encodings can cause problems. In this case, we are on Windows and copying text between Word and R, and Word on Windows uses a different encoding than R on Windows. In the conversion from the Word encoding to the R encoding, the "ā" has been converted to a normal "a".
Next, we try using a special escape sequence, "\u101", in our code for the ā character. In R, an escape sequence of the form "\unnnn" specifies a UNICODE code point (The Unicode Consortium, 2018). This is one way to directly input "ā" to R and it avoids the conversion problem because we are not transferring the "ā" character from one application to another.
barplot(speakers$Percent, names.arg=speakers$Census, ylab="Percent", main="Speakers of te reo M\u101ori in the M\u101ori ethnic group", family="Microsoft New Tai Lue")
Unfortunately, that just produces an empty rectangle in the plot.
The problem here is with the font that we are using. We are now correctly specifying the character that we want, but that character does not exist in the font we are using, so we just get an empty rectangle.
Next, we try a different font. We specify the font family "sans", which on Windows is the Arial font.
barplot(speakers$Percent, names.arg=speakers$Census, ylab="Percent", main="Speakers of te reo M\u101ori in the M\u101ori ethnic group", family="sans")
Finally, we get the correct result on screen.
Unfortunately, when we save the screen plot to PDF format for inclusion in a report, the "ā" mysteriously changes back to a normal "a"; the macron disappears.
pdf() barplot(speakers$Percent, names.arg=speakers$Census, ylab="Percent", main="Speakers of te reo M\u101ori in the M\u101ori ethnic group", family="sans") dev.off()
Here we have another encoding problem, but this time R is using a different encoding for a character vector compared to the encoding that it uses for the PDF graphics device. In the conversion from a character vector to the PDF file, the "ā" has been converted to a normal "a".
So in terms of producing text in R graphics, the things we need to be aware of are how we input the text, the fonts we are using, and the encodings we are using, with the latter depending (at least) on our operating system and the graphics device we are using.
This section provides some solutions for the problems described above.
Working backwards, one quick way to solve the encoding problem with the PDF graphics device is not to use PDF. If we can see the right result on screen, then we should be able to reproduce that result with a raster format, like PNG. This will not produce as nice a result as the vector PDF version and we may have to play with the resolution of the PNG to get a good result for use in a report, but the characters should at least look correct.
png() barplot(speakers$Percent, names.arg=speakers$Census, ylab="Percent", main="Speakers of te reo M\u101ori in the M\u101ori ethnic group", family="sans") dev.off()
If we really want PDF output, another simple option is to
use the PDF graphics device that is provided by the
cairo_pdf function (instead of the standard PDF device
that is provided by the pdf function).
The cairo_pdf
device uses the same encoding as the "\u101" character
string, so there is no conversion of the "ā" character.
cairo_pdf() barplot(speakers$Percent, names.arg=speakers$Census, ylab="Percent", main="Speakers of te reo M\u101ori in the M\u101ori ethnic group", family="sans") dev.off()
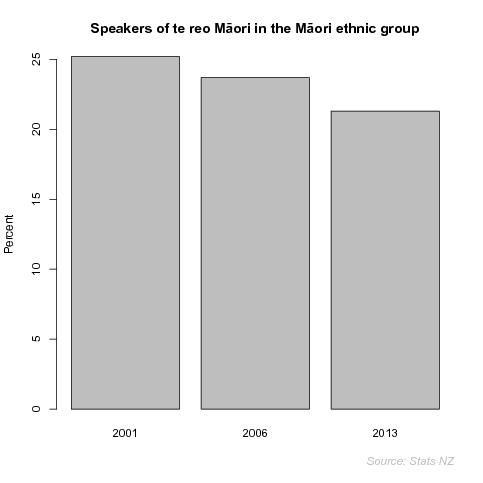
The cairo_pdf device works because it is based on the
Cairo Graphics library. The standard SVG graphics device
(provided by the svg function) is also
based on Cairo Graphics, so it works with this example too.
In the scenario above, we started off using a non-standard font that did not contain the "ā" character and switched back to the standard "sans" font in order to get a font that contained the "ā" character. Another possible solution is that the font contains just the accent that we want and we can combine it with a normal character. The code below does this by using the original non-standard font and specifying the text "a\u304", where the escape sequence "\u304" specifies the UNICODE code point for a combining macron accent.
barplot(speakers$Percent, names.arg=speakers$Census, ylab="Percent", main="Speakers of te reo Ma\u304ori in the Ma\u304ori ethnic group", family="Microsoft New Tai Lue")
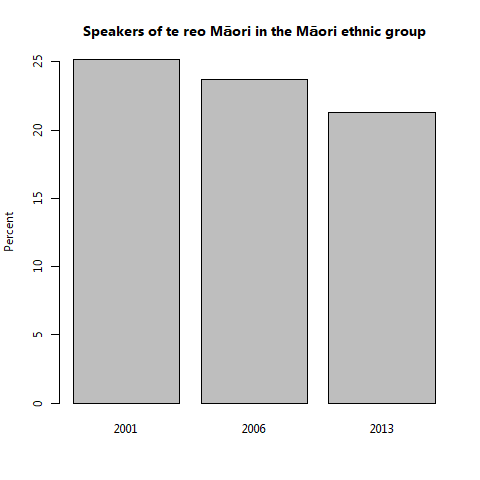
Yet another possibility is that we want to specify a character that is unusual and is not in a standard font, so we need to tell R to use a particular font. How we do that depends on our operating system and the graphics format we want to produce.
On Linux, with Cairo graphics support, we should be able to simply specify the name of any font that has been installed on our system in order to produce plots on screen (and in raster formats).
However, for Windows, and for PDF output, we need to register a font with R first. For example, the following code registers the "Microsoft New Tai Lue" font for use with R graphics on Windows.
WindowsFonts("Microsoft New Tai Lue"=WindowsFont("Microsoft New Tai Lue"))
Once that code has been run, we can use "Microsoft New Tai Lue" in
the family paramter of the barplot function
to specify the use of that font for text.
The corresponding functions for registering fonts for PDF output
are pdfFonts and Type1Font.
The 'extrafont' package simplifies the Windows and/or PDF set up
through its font_import and loadfonts functions,
which will register all available system fonts for use with
Windows and/or PDF.
The cairo_pdf PDF device
allows us to just use the names of system fonts without having
to register anything.
Typing an "ā" character directly into R is not straightforward and depends on our operating system and the R interface that we are using.
As has been demonstrated, one approach is to type a UNICODE code point escape sequence, like "\u101". The disadvantage of this is that it requires a lot of typing. On the other hand, because the escape sequence just uses standard characters, there are no encoding issues. This should work on all operating systems and with all R interfaces. It is also very portable (e.g., if we want to share our code with others). We can also even use text substitution to relieve the typing burden (as demonstrated by Michael Scroggie). The table below shows the code points (decimal) and R escape sequences for the macron-accented characters required for written Mā"ori.
| 257 | "\u101" | ā | 256 | "\u100" | Ā | |
| 275 | "\u113" | ē | 274 | "\u112" | Ē | |
| 299 | "\u12b" | ī | 298 | "\u12a" | Ī | |
| 333 | "\u14d" | ō | 332 | "\u14c" | Ō | |
| 363 | "\u16b" | ū | 362 | "\u16a" | Ū |
If we want to explicitly type a macron-accented character, it is possible to have a keyboard with macron-accented characters, like the one sold by te reo learning media, in which case we require a single key stroke, though this may only work with Windows or macOS.
On Windows, the operating system allows us to type a UNICODE code point followed by Alt-x (e.g., 101 followed by Alt-x), but this is not supported by all software. For example, this works in Word, but unfortunately not in Rgui or RStudio.
It is also possible to set up a Māori keyboard on Windows and then the key sequence ` (backtick) followed by "a" produces an "ā". Again, this requires support in software applications and does not work in Rgui. However, this does work in RStudio.
Part of the original problem, which involved cutting and pasting text from another software application into R, was due to running R on Windows. A radical solution to that part of the problem is not to run Windows. R on Linux uses the same encoding as most other Linux software, so the cutting-and-pasting issue disappears. For example, we can write code that includes an "ā" in Emacs and safely cut-and-paste into R.
If we are working on Linux, there is an operating system key sequence Ctrl-Shift-u followed by UNICODE code point. This works when running R in the shell, but not in RStudio or Emacs. It is also possible to set up a Māori keyboard and define a compose key then type the composeKey followed by - (dash) followed by "a" to produce an "ā" character. This works in the shell and RStudio, but not Emacs. Of course, Emacs being Emacs, we can define any keyboard shortcut we like. For example, adding the following to our .emacs file allows us to type <F9> followed by "a" to produce "ā".
(define-key key-translation-map (kbd "<f9> a") (kbd "ā"))There is also a general Emacs keystroke sequence Ctrl-x 8 <RET> followed by a UNICODE code point <RET>, though it is less appropriate to call that a "shortcut".
Behind many of the issues already described lurks the idea of character encodings. A character encoding describes a mapping between characters like "a" and "ā" and how those characters are stored in computer memory. For example, R on Windows uses an encoding called CP1252. This is a single-byte encoding (it uses only a single byte to represent characters) so it is limited to 256 (2^8) different characters. The character "a" is stored as the number 97 (61 in hexadecimal notation), but there is no representation for "ā" at all. R on Linux uses an encoding called UTF-8, which is a multi-byte encoding. This means that it can represent all characters for all languages. For example, the character "a" is stored as the number 97 (61 hexadecimal) in a single byte and the character "ā" is stored using two bytes containing the numbers 196 and 129 (C4 81 in hexadecimal).
It is crucial to know what encoding is being used for a piece of text. For example, if we have a series of three bytes of computer memory containing 97, 196, and 129 (61 C4 81), this could be interpreted as either "aā" using UTF-8 or "aÄ" using CP1252 (196 is Ä in CP1252 and 129 is undefined).
We can demonstrate this in R by changing the encoding that R uses for character values. The following code (for Linux) first sets the character encoding to ISO-8859-1 (which is similar to CP1252), interprets three bytes as characters, then set the encoding to UTF-8 and interprets the same three bytes as different characters.
Sys.setlocale("LC_CTYPE", "en_NZ.iso88591")
[1] "en_NZ.iso88591"
rawToChar(as.raw(c(97, 196, 129)))
[1] "aÄ\201"
Sys.setlocale("LC_CTYPE", "en_NZ.UTF-8")
[1] "en_NZ.UTF-8"
rawToChar(as.raw(c(97, 196, 129)))
[1] "aā"
If we know the encoding of a piece of text (a series of bytes), we can convert from one to another, but not all conversions will be successful because, as shown above, some encodings contain more characters than others. In the examples below, the letter "a" converts happily from UTF-8 to CP1252, but attempting to convert "ā" from UTF-8 to CP1252 results in either a missing value or a normal "a" character.
iconv("a", from="UTF-8", to="CP1252")
[1] "a"
iconv("\u101", from="UTF-8", to="CP1252")
[1] NA
iconv("\u101", from="UTF-8", to="CP1252//TRANSLIT")
[1] "a"
The above description and demonstration hopefully helps to explain how the original cut-and-paste problem occurred (R on Windows was using one encoding for input and Word was a different encoding and the conversion between encodings changed "ā" to "a").
The other encoding problem occurred when we tried to produce a PDF version of a plot that looked correct on screen. The problem here was that the R PDF device uses the single-byte encoding ISO-8859-1, but the character vector for the plot label contained "M\u101ori", which R stores using UTF-8. The conversion from the UTF-8 character vector to the ISO-8859-1 PDF file changed "ā" to "a".
iconv("\u101", from="UTF-8", to="ISO-8859-1//TRANSLIT")
[1] "a"
Armed with a little knowledge about what is causing the problem,
it is possible to construct a solution in this case.
The key is that we need to specify for the PDF device
a single-byte encoding that contains
the "ā" character (plus other macron-accented characters).
Fortunately, the pdf
function has an encoding argument that allows
us to specify an encoding file.
R comes with several standard encoding files, including ISOLatin1.enc (for
ISO-8859-1), WinAnsi.enc (for CP1252), and ISOLatin7.enc, which is an
encoding that contains macron-accented characters.
The lines of the ISOLatin7.enc file that refer to macron-accented
characters are shown below and we can see that, for example,
amacron is entry number 226 (342 in octal notation).
%% 0300 /Aogonek /Iogonek /Amacron /Cacute /Adieresis /Aring /Eogonek /Emacron /Ccaron /Eacute /Zacute /Edotaccent /Gcommaaccent /Kcommaaccent /Imacron /Lcommaaccent /Scaron /Nacute /Ncommaaccent /Oacute /Omacron /Otilde /Odieresis /multiply /Uogonek /Lslash /Sacute /Umacron /Udieresis /Zdotaccent /Zcaron /germandbls %% 0340 /aogonek /iogonek /amacron /cacute /adieresis /aring /eogonek /emacron /ccaron /eacute /zacute /edotaccent /gcommaaccent /kcommaaccent /imacron /lcommaaccent /scaron /nacute /ncommaaccent /oacute /omacron /otilde /odieresis /divide /uogonek /lslash /sacute /umacron /udieresis /zdotaccent /zcaron /quoteright
To get this to work, we also need to make sure that R is using the same encoding as we want to use in the PDF file, by setting the character encoding that R is using. If we did not do this, we would run into problems with converting characters between different encodings, and we all know how badly that goes.
The following code shows an example for Windows.
First, we set the R character vector encoding to CP1257 (the
Windows equivalent of ISO-Latin-7), then we open a pdf
device with encoding ISO-Latin-7, then we specify the "ā"
character using the octal escape sequence "\342".
At the end we switch back to the character encoding that we
started with.
## Windows Sys.setlocale("LC_CTYPE", "Greek_Greece.1257") pdf(compress=FALSE, encoding="ISOLatin7.enc", width=5, height=1) barplot(speakers$Percent, names.arg=speakers$Census, ylab="Percent", main="Speakers of te reo M\342ori in the M\342ori ethnic group") dev.off() ## Reset Sys.setlocale("LC_CTYPE", "English_New Zealand.1252")
Another way to avoid the character encoding conversions is to stick to the ASCII range of characters because (almost) all encodings are (almost) the same in that range. To do this we can create a custom encoding file. For example, the first few lines of a custom encoding file called "macrons.enc" is shown below, with the macron-accented vowels at positions 16 to 28 (20 to 34 in octal notation).
/macrons [
/.notdef /.notdef /.notdef /.notdef /.notdef /.notdef /.notdef /.notdef
/.notdef /.notdef /.notdef /.notdef /.notdef /.notdef /.notdef /.notdef
/Amacron /Emacron /Imacron /Omacron /Umacron /.notdef /.notdef /.notdef
/amacron /emacron /imacron /omacron /umacron /.notdef /.notdef /.notdef
%% 040
/space /exclam /quotedbl /numbersign /dollar /percent /ampersand
/quoteright /parenleft /parenright /asterisk /plus /comma /hyphen /period /slash
%% 060
/zero /one /two /three /four /five /six /seven /eight /nine
The following code uses that encoding file and specifies macron-accented characters via octal escape sequences. In this example, we are using the 'grid' package to just draw the accented characters by themselves on the page.
library(grid)
pdf("PDF/macrons.pdf", compress=FALSE, encoding="./PDF/macrons.enc", width=5, height=1) grid.text("\020 \021 \022 \023 \024 \030 \031 \032 \033 \034", gp=gpar(cex=3)) dev.off()
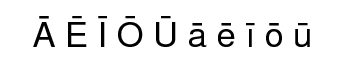
Another important detail, especially if a PDF plot is to be
embedded within a larger report, such as a LaTeX document, is
to make sure that the font is embedded in the PDF file.
This happens automatically if we use the cairo_pdf
graphics device, but if we use the standard pdf
device, we can use the embedFonts function,
as shown below.
embedFonts("PDF/macrons.pdf", outfile="PDF/macrons-embed.pdf")
There are three issues involved with correctly producing macron-accented text in R graphics:
cairo_pdf device.
The problems that can arise and the exact solutions will depend on which operating system (version) and which version of R we are using and which interface to R we are using (at least). All of the examples used in this document were run on either Windows or Linux (Windows 10 and Ubuntu 16.04 to be more precise) and all examples were run on a recent version of R (3.4.0 at least). Some of the statements in this document are therefore too sweeping and general and will no doubt be untrue for some combinations of operating system and R version. While there are too many combinations of different operating systems, different software and different software versions to cover all possibilities, if we encounter a combination not covered explicitly in this document, hopefully the general ideas of input methods, fonts, and encodings will help to explore and discover an effective solution.
Kupu o te Rā is a Māori word-of-the-day web site. It includes information on how to enter macron-accented characters in different Operating Systems and how to obtain font support.
The Māori Language Commission's Guidelines for Māori Language Orthography contains detailed information about when to use (and when not to use) macrons in written Māori.
Stephen Cope (Kimihia), has a page about typing Māori easily and Unicode Macros, mainly for Te Reo Māori. Stephen also links to an online Māori keyboard.
Michael Scroggie has a blog post where he defines a simple function to substitute special character sequences with Unicode escape sequences to get Māori accents in R graphics.
pdf device.
Murrell, P. (2018). "Putting the Macron in Māori: Accented Characters in R Graphics." Technical Report 2018-03, Department of Statistics, The University of Auckland. [ bib ]
This document
by Paul
Murrell is licensed under a Creative
Commons Attribution 4.0 International License.