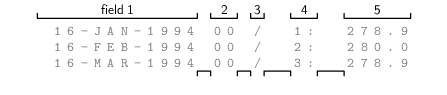Subsections
5.2 Plain text formats
The simplest way to store information in computer memory
is as a single file with a plain
text format.
Plain text files can be thought of as the lowest common denominator of
storage formats; they might not be the most efficient or sophisticated
solution, but we can be fairly certain that they will get the job done.
The basic conceptual structure of a plain text format is that the data are
arranged in rows, with several values stored on each row.
It is common for there to be several rows of general information
about the data set, or metadata,
at the start of the file.
This is often referred to as a file header.
A good example of a data set in a plain text format is the surface temperature
data for the Pacific Pole of Inaccessibility (see
Section 1.1). Figure 5.2
shows how we would normally see this sort of plain text file
if we view it in a text editor or a web browser.
Figure 5.2:
The first few lines of the plain text output from the Live Access Server
for the surface temperature at Point Nemo. This is
a reproduction of Figure 1.2.
VARIABLE : Mean TS from clear sky composite (kelvin)
FILENAME : ISCCPMonthly_avg.nc
FILEPATH : /usr/local/fer_data/data/
SUBSET : 48 points (TIME)
LONGITUDE: 123.8W(-123.8)
LATITUDE : 48.8S
123.8W
23
16-JAN-1994 00 / 1: 278.9
16-FEB-1994 00 / 2: 280.0
16-MAR-1994 00 / 3: 278.9
16-APR-1994 00 / 4: 278.9
16-MAY-1994 00 / 5: 277.8
16-JUN-1994 00 / 6: 276.1
...
|
This file has 8 lines of metadata at the start, followed by 48 lines
of the core data values, with 2 values, a date and a temperature, on each row.
There are two main sub-types of plain text format,
which differ in how separate values are
identified within a row:
- Delimited formats:
-
In a delimited format,
values within a row are separated by
a special character, or delimiter. For example,
it is possible to view the file in
Figure 5.2 as a delimited format,
where each line after the header
consists of two fields
separated by a colon
(the character `:' is the delimiter).
Alternatively, if we used whitespace
(one or more spaces or tabs)
as the delimiter, there would be five fields, as shown below.
- Fixed-width formats:
-
In a fixed-width format,
each value is allocated a fixed number of characters within every row.
For example,
it is possible to view the file in Figure 5.2
as a fixed-width format, where
the first value uses the first 20 characters and the second value
uses the next 8 characters. Alternatively, there are five values on each row
using 12, 3, 2, 6, and 5 characters respectively, as shown
in the diagram below.
At the lowest level, the primary characteristic of a plain text format
is that all of the information in the file, even numeric information,
is stored as text.
We will spend the next few sections at this lower level
of detail because it will be helpful in understanding
the advantages and disadvantages of plain text formats
for storing data, and because it will help us to
differentiate plain text formats from binary formats later on
in Section 5.3.
The first things we need to establish are some fundamental ideas
about computer memory.
5.2.1 Computer memory
The most fundamental unit of computer memory is the bit.
A bit can be a tiny magnetic region on a hard disk,
a tiny dent in the reflective material on a CD or DVD,
or a tiny transistor on a memory stick. Whatever the
physical implementation, the important thing to know about
a bit is that, like a switch,
it can only take one of two values: it is either “on”
or “off”.
A collection of 8 bits is called a byte and
(on the majority of
computers today) a collection of 4 bytes, or 32 bits, is called a
word.
A file is simply a block of computer memory.
A file can be as small as just a few bytes
or it can be several gigabytes in size (thousands of millions of bytes).
A file format
is a way of interpreting the bytes in a file.
For example, in the simplest case, a plain text format means that
each byte is used to represent a single character.
In order to visualize the idea of file formats, we will
display a block of memory in the format shown below.
This example shows the first 24 bytes from the PDF file
for this book.
0 : 00100101 01010000 01000100 01000110 | %PDF
4 : 00101101 00110001 00101110 00110100 | -1.4
8 : 00001010 00110101 00100000 00110000 | .5 0
12 : 00100000 01101111 01100010 01101010 | obj
16 : 00001010 00111100 00111100 00100000 | .<<
20 : 00101111 01010011 00100000 00101111 | /S /
This display has three columns. On the left is a byte offset that
indicates the memory location within the file for each row.
The middle column displays the raw memory contents of the file,
which is just a series of 0's and 1's.
The right hand column displays an interpretation of the bytes.
This display is split across several rows just so that it will fit onto
the printed page. A block of computer memory is best thought of as
one long line of 0's and 1's.
In this example, we are interpreting each byte of memory as a single character,
so for each byte in the middle column, there is a corresponding
character in the right-hand column. As specific examples,
the first byte,
00100101,
is being interpreted as the percent character, %, and
and the second byte,
01010000,
is being interpreted as the letter P.
In some cases, the
byte of memory does not correspond to a printable character, and in those
cases we just display a full stop. An example of this is byte number
nine (the first byte on the third row of the display).
Because the binary code for computer memory takes up so much space, we
will also sometimes display the central raw memory column using
hexadecimal (base 16)
code rather than binary. In this case, each byte of memory
is just a pair of hexadecimal digits. The first 24 bytes
of the PDF file for this book
are shown again below, using hexadecimal code for the raw memory.
0 : 25 50 44 46 2d 31 2e 34 0a 35 20 30 | %PDF-1.4.5 0
12 : 20 6f 62 6a 0a 3c 3c 20 2f 53 20 2f | obj.<< /S /
We will now look at a low level at the surface temperature
data for the Pacific Pole of Inaccessibility (see
Section 1.1), which is in a plain text format.
To emphasize the format of this information in computer memory,
the first 48 bytes of the file are displayed below. This display
should be compared with Figure 5.2,
which shows what we would normally see when we view the plain
text file in a text editor or web browser.
0 : 20 20 20 20 20 20 20 20 20 20 20 20 |
12 : 20 56 41 52 49 41 42 4c 45 20 3a 20 | VARIABLE :
24 : 4d 65 61 6e 20 54 53 20 66 72 6f 6d | Mean TS from
36 : 20 63 6c 65 61 72 20 73 6b 79 20 63 | clear sky c
This display clearly demonstrates that the Point Nemo information
has been stored as a series of characters. The empty space at the
start of the first line is a series of 13 spaces, with each space
stored as a byte with the hexadecimal value 20. The
letter V at the start of the word VARIABLE has been
stored as a byte with the value 56.
To further emphasize the character-based nature of a plain text format,
another part of the file is shown below as raw computer memory, this
time focusing on the part of the file that contains the core data--the
dates and temperature values.
336 : 20 31 36 2d 4a 41 4e 2d 31 39 39 34 20 30 30 | 16-JAN-1994 00
351 : 20 2f 20 20 31 3a 20 20 32 37 38 2e 39 0d 0a | / 1: 278.9..
366 : 20 31 36 2d 46 45 42 2d 31 39 39 34 20 30 30 | 16-FEB-1994 00
381 : 20 2f 20 20 32 3a 20 20 32 38 30 2e 30 0d 0a | / 2: 280.0..
The second line of this display shows that the number 278.9
is stored in this file as five characters--the
digits 2, 7, 8,
followed by a full stop, then the digit 9--with one byte per
character. Another small detail that may not have been clear
from previous views of these data is that each line starts with a space,
represented by a byte with the value 20.
We will contrast this sort of format with other ways of storing the
information later in Section 5.3. For now,
we just need to be aware of the simplicity of the
memory
usage in such a plain text format and the fact that everything
is stored as a series of characters in a plain text format.
The next section will look at why these features can be both a blessing and
a curse.
5.2.4 Advantages and disadvantages
The main advantage of plain text formats is their simplicity:
we do not require complex software to create or view a text file and
we do not need esoteric skills beyond being able to type
on a keyboard, which means that it is easy for people
to view and modify the data.
The simplicity of plain text formats
means that virtually all software packages can read and
write text files and
plain text files are portable across different computer
platforms.
The main disadvantage of plain text formats is also their simplicity.
The basic conceptual structure of rows of values
can be very inefficient and inappropriate for data sets with
any sort of complex structure.
The
low-level format of storing everything as characters, with one
byte per character, can also be very inefficient in terms of the amount
of computer memory required.
Consider a data set collected on two families, as depicted in
Figure 5.3. What would this look like as a
plain text file, with one row for all of the information about each
person in the data set? One possible fixed-width format is shown below.
In this format, each row records the information for one person. For
each person, there is
a column for the father's name (if known), a column for the mother's name
(if known), the person's own name, his or her age, and his or her gender.
John 33 male
Julia 32 female
John Julia Jack 6 male
John Julia Jill 4 female
John Julia John jnr 2 male
David 45 male
Debbie 42 female
David Debbie Donald 16 male
David Debbie Dianne 12 female
This format for storing these data is not ideal for two reasons.
Firstly, it is not efficient; the parent information is repeated
over and over again. This repetition is also undesirable because
it creates opportunities for errors and inconsistencies to
creep in. Ideally, each individual piece of information would
be stored exactly once; if more than one copy
exists, then it is possible for the copies to disagree.
The DRY principle
(Section 2.7) applies to data
as well as code.
The second problem is not as obvious, but is arguably much more
important. The fundamental structure of most plain text file formats
means that each line of the file contains exactly one record
or case in the data set. This works well when a data set
only contains information about one type of object, or, put another way,
when the data set itself has a “flat” structure.
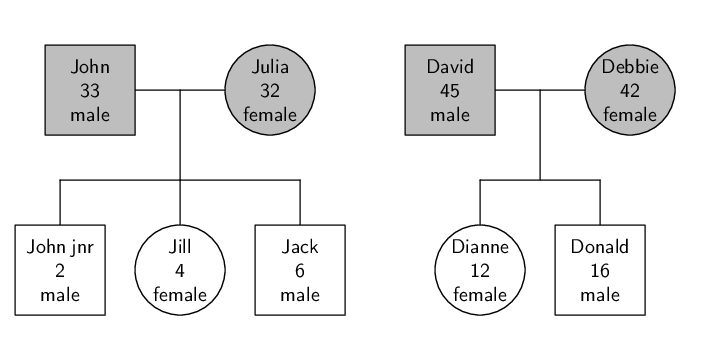
The data set of family members does not have a flat structure.
There is information about two different types of object, parents
and children, and these objects have a definite relationship between them.
We can say that the data set is hierarchical
or multi-level or
stratified (as is obvious from the view of the data in
Figure 5.3).
Any data set that is obtained using a non-trivial
study design is likely to have a
hierarchical structure like this.
In other words, a plain text file format does not allow for
sophisticated data models.
A plain text format is unable to provide an appropriate
representation of a complex data structure. Later sections will
provide examples of storage formats that are capable of storing
complex data structures.
Figure 5.3:
An example of hierarchical data: a family tree
containing data on parents (grey) and children (white).
 |
Another major weakness of free-form text files is the lack of
information within the file itself about the structure
of the file. For example, plain text files do not usually
contain information about which
special character is being used to separate fields in a delimited file,
or any information about the widths of fields with a
fixed-width format. This means that the computer cannot
automatically determine where different fields are within each
row of a plain text file, or even how many fields there are.
A fixed-width format avoids this problem,
but enforcing a fixed length for fields can create other
difficulties if we do not know the maximum possible length for all
variables.
Also, if the values for a variable can have very different lengths,
a fixed-width format can be inefficient because we store lots
of empty space for short values.
The simplicity of plain text files make it easy for a computer
to read a file as a series of characters, but the computer cannot
easily distinguish individual data values from the series of characters.
Even worse, the computer has no way of telling what sort of data is
stored in each field. Does the series of characters represent a number,
or text, or some more complex value such as a date?
In practice, a human must supply
additional information about a plain text file before the computer
can successfully determine where the different fields are within a
plain text file and what sort of value is stored in each field.
5.2.5 CSV files
The Comma-Separated Value (CSV) format is a special case of a
plain text format.
Although not a formal standard, CSV files
are very common and are a quite reliable plain text delimited
format that at least solves the problem of where the fields
are in each row of the file.
The main rules for the CSV format are:
- Comma-delimited:
-
Each field is separated by a comma (i.e., the
character , is the delimiter).
- Double-quotes are special:
-
Fields containing commas must be surrounded by double-quotes
(i.e., the " character is special).
- Double-quote escape sequence:
-
Fields containing double-quotes must be surrounded by
double-quotes and each embedded double-quote must
be represented using two double-quotes
(i.e., within double-quotes,
"" is an escape sequence
for a literal double-quote).
- Header information
-
There can be a single header line containing the names
of the fields.
CSV files are a common way to transfer data from a spreadsheet
to other software.
Figure 5.4 shows what the Point Nemo
temperature data might look like in a CSV format. Notice that
most of the metadata cannot be included in the file when using
this format.
Figure 5.4:
The first few lines of the plain text output from the Live Access Server
for the surface temperature at Point Nemo in Comma-Separated Value
(CSV) format.
On each line, there are two data values, a date and a temperature value,
separated from each other
by a comma. The first line provides a name for each column of data values.
date,temp
16-JAN-1994,278.9
16-FEB-1994,280
16-MAR-1994,278.9
16-APR-1994,278.9
16-MAY-1994,277.8
16-JUN-1994,276.1
...
|
A common feature of plain text files is that data values are usually
arranged in rows, as we have seen in Figures 5.2
and 5.4.
We also know that plain text files are, at the low level
of computer memory, just a series of characters.
How does the computer know where one line ends and the next line starts?
The answer is that the end of a line in a text file is indicated by a special
character (or two special characters). Most software that we use to
view text files does not explicitly show us these characters. Instead,
the software just starts a new line.
To demonstrate this idea, two lines from the file pointnemotemp.txt
are reproduced below (as they appear when viewed in a
text editor or web browser).
16-JAN-1994 00 / 1: 278.9
16-FEB-1994 00 / 2: 280.0
The section of computer memory
used to store these two lines
is shown below.
336 : 20 31 36 2d 4a 41 4e 2d 31 39 39 34 20 30 30 | 16-JAN-1994 00
351 : 20 2f 20 20 31 3a 20 20 32 37 38 2e 39 0d 0a | / 1: 278.9..
366 : 20 31 36 2d 46 45 42 2d 31 39 39 34 20 30 30 | 16-FEB-1994 00
381 : 20 2f 20 20 32 3a 20 20 32 38 30 2e 30 0d 0a | / 2: 280.0..
The feature to look for is the section of two
bytes immediately after each temperature value. These two
bytes have the values 0d and 0a, and this is
the special byte sequence that is used to indicate the end of
a line in a plain text file.
As mentioned above, these bytes are not explicitly shown by
most software that we use to view the text file. The software
detects this byte sequence and starts a new line in response.
So why do we need to know about the special byte sequence at all?
Because, unfortunately, this is not the only byte sequence used
to signal the end of the line. The sequence 0d 0a
is common for plain text files that have been created on a Windows
system, but for plain text files created on a Mac OS X or Linux system,
the sequence is likely to be just 0a.
Many computer programs will allow for this possibility and cope
automatically, but it can be a source of problems. For example,
if a plain text file that was created on Linux is opened using
Microsoft Notepad, the entire file is treated as if it is one long
row, because Notepad expects to see 0d 0a for a line ending
and the file will only contain 0a at the end of each line.
5.2.7 Text encodings
We have identified two features of plain text formats so far:
all data is stored as
a series of characters and each character is stored
in computer memory using a single byte.
The second part, concerning how a single character is stored in
computer memory, is called a character encoding.
Up to this point we have only considered
the simplest possible character encoding.
When we only have the letters, digits,
special symbols, and punctuation marks that appear on
a standard (US) English keyboard, then we can use a single
byte to store each character. This is called an
ASCII
encoding (American Standard Code for Information Interchange).
An encoding that uses a single byte (8 bits) per character can cope with
up to 256 (28) different characters, which is plenty
for a standard English keyboard.
Many other languages have some characters in common with English
but also have accented characters, such as é and ö.
In each of these cases, it is still possible to use an encoding
that represents each possible
character in the language with a single byte. However, the problem is that
different encodings may use the same byte value for a different
character. For example, in the Latin1
encoding, for Western European languages,
the byte value f1 represents the character ñ, but in
the Latin2
encoding, for Eastern European languages, the byte value
f1 represents the character ń.
Because of this ambiguity, it is important to know what encoding was used
when the text was stored.
The situation is much more complex for
written languages in some Asian and Middle Eastern countries
that use several thousand different characters
(e.g., Japanese Kanji ideographs). In order to store
text in these languages, it is necessary to use a
multi-byte
encoding scheme where more than one byte is used to store
each character.
UNICODE is an attempt to allow computers to work with
all of the characters in all of the languages
of the world. Every character has its own number, called
a “code point”,
often written in the form U+xxxxxx, where every
x is a hexadecimal digit. For example,
the letter `A' is U+000041
and the letter `ö' is U+0000F6.
There are two main “encodings” that are used
to store a UNICODE code point in memory.
UTF-16 always uses two bytes per character of text and
UTF-8 uses one or more bytes,
depending on which characters are stored. If the text
is only ASCII, UTF-8 will only use one byte per character.
For example, the text “just testing” is shown below
saved via Microsoft's Notepad with a plain text format, but using three
different encodings: ASCII, UTF-16, and UTF-8.
0 : 6a 75 73 74 20 74 65 73 74 69 6e 67 | just testing
The ASCII format contains exactly one byte per character.
0 : ff fe 6a 00 75 00 73 00 74 00 20 00 | ..j.u.s.t. .
12 : 74 00 65 00 73 00 74 00 69 00 6e 00 | t.e.s.t.i.n.
24 : 67 00 | g.
The UTF-16 format differs from the ASCII format in two ways.
For every byte in the ASCII file, there are now two bytes, one
containing the hexadecimal code we saw before followed by a byte
containing all zeroes. There are also two additional bytes
at the start. These are called a byte order mark
(BOM)
and indicate the order of the two bytes that make
up each letter in the text, which is used by software when
reading the file.
0 : ef bb bf 6a 75 73 74 20 74 65 73 74 | ...just test
12 : 69 6e 67 | ing
The UTF-8 format is mostly the same as the ASCII format; each
letter has only one byte, with the same binary code as before
because these are all common English letters.
The difference is that there are three bytes at the start
to act as a BOM. Notepad writes a BOM like this at the start of
UTF-8 files, but not all software does this.
In summary, a plain text format always stores all data values as
a series of characters. However, the number of bytes
used to store each character in computer memory depends on the
character encoding that is used.
This encoding is another example of additional information that
may have to be provided by a human before the computer can read
data correctly from a plain text file, although many software
packages will cope with different encodings automatically.
5.2.8 Case study: The Data Expo
The American Statistical Association (ASA) holds an annual conference
called the Joint Statistical Meetings (JSM).
One of the events sometimes held at
this conference is a Data Exposition, where contestants are provided with a
data set and must produce a poster demonstrating a comprehensive analysis of
the data. For the Data Expo at the 2006
JSM,5.1the data were geographic and atmospheric measures that
were obtained from NASA's
Live Access Server (see Section 1.1).
The variables in the data set are:
elevation, temperature (surface and air), ozone, air pressure,
and cloud cover (low, mid, and high).
With the exception of elevation, all variables are monthly averages,
with observations for January 1995 to December 2000.
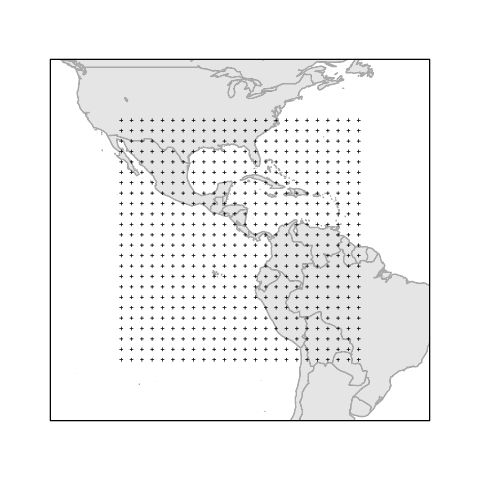
The data are measured at evenly spaced geographic locations
on a very coarse 24 by 24 grid covering Central America
(see Figure 5.5).
Figure 5.5:
The geographic locations at which Live Access Server atmospheric data were obtained
for the 2006 JSM Data Expo.
|
|
The data were downloaded from the Live Access Server in a plain text format
with one file for each
variable, for each month; this produced 72 files per atmospheric variable,
plus 1 file for elevation, for a total of 505 files.
Figure 5.6 shows the start of one of the
surface temperature files.
Figure 5.6:
The first few lines of output from the Live Access Server
for the surface temperature of the earth for January 1995,
over a coarse 24 by 24 grid of locations covering Central America.
VARIABLE : Mean TS from clear sky composite (kelvin)
FILENAME : ISCCPMonthly_avg.nc
FILEPATH : /usr/local/fer_dsets/data/
SUBSET : 24 by 24 points (LONGITUDE-LATITUDE)
TIME : 16-JAN-1995 00:00
113.8W 111.2W 108.8W 106.2W 103.8W 101.2W 98.8W ...
27 28 29 30 31 32 33 ...
36.2N / 51: 272.7 270.9 270.9 269.7 273.2 275.6 277.3 ...
33.8N / 50: 279.5 279.5 275.0 275.6 277.3 279.5 281.6 ...
31.2N / 49: 284.7 284.7 281.6 281.6 280.5 282.2 284.7 ...
28.8N / 48: 289.3 286.8 286.8 283.7 284.2 286.8 287.8 ...
26.2N / 47: 292.2 293.2 287.8 287.8 285.8 288.8 291.7 ...
23.8N / 46: 294.1 295.0 296.5 286.8 286.8 285.2 289.8 ...
...
|
This data set demonstrates a number of advantages and limitations of
a plain text format for storing data. First of all, the data is
very straightforward to access because it does not need sophisticated
software. It is also easy for a human to view the data and understand
what is in each file.
However, the file format provides a classic demonstration of the
typical lack of standardized structure in plain text files. For example,
the raw data values only start on the eighth line of the file, but
there is no indication of that fact within the file itself. This is not
an issue for a human viewing the file, but a computer has no chance of
detecting this structure automatically. Second, the raw data are
arranged in a matrix, corresponding to a geographic grid of locations, but
again there is no inherent indication of this structure. For example,
only a human can tell that the first 11 characters on each line of
raw data are row labels describing latitude.
The “header” part of the file (the first seven lines) contains
metadata, including information about which variable is recorded in the
file and the units used for those measurements. This is very important
and useful
information, but again it is not obvious (for a computer) which bits are
labels and which bits are information, let alone what sort of information
is in each bit.
Finally, there is the fact that the data reside in 505 separate files.
This is essentially an admission that plain text files are not suited
to data sets with anything beyond a simple two-dimensional matrix-like
structure. In this case, the temporal dimension--the
fact that data are recorded at multiple
time points--and the multivariate nature of the data--the
fact that multiple variables are recorded--leads to there being separate
files for each variable and for each time point.
Having the data spread across many files
creates issues in terms of the naming of files, for example, to
ensure that all files from the same date, but containing different variables,
can be easily located. There is also a reasonable amount of redundancy,
with metadata and labels repeated many times over in different files.
We will look at another way to store this information in
Section 5.6.5.
A plain text format is a simple, lowest-common-denominator
storage format.
Data in a plain text format are usually arranged in rows,
with several values on each row.
Values within a row are separated from each other by a delimiter
or each value is allocated a fixed number of characters within a row.
The CSV format is a comma-delimited format.
All data values in a plain text file are stored as a series of characters.
Even numbers are stored as characters.
Each character is stored in computer memory as one or two bytes.
The main problem with plain text files is that the file itself contains
no information about where the data values are within the file
and no information about whether the data values represent numbers or
text, or something more complex.
Paul Murrell

This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 New Zealand License.