
by Paul Murrell
This report provides an update on a previous report, "An OpenAPI Pipeline for CPI Data", which described the construction of an OpenAPI pipeline to produce a plot of CPI data. Two issues were identified with the original pipeline: the system requirements necessary to run the pipeline were significant; and the system requirements necessary just to run the OpenAPI glue system, the R package 'conduit', while much less, were still a potential obstacle to use of the pipeline by a lay audience. This report demonstrates solutions for both issues: a new "host" mechanism for OpenAPI modules to satisfy module system requirements; and an example of a user-friendly web front-end for running OpenAPI pipelines in 'conduit'.
The OpenAPI pipeline that was described in the previous report has three modules: a data module that downloads a CSV of CPI data from a web location to a local file; a script module that extracts R code from an XML file on the web; and a plot module that executes the R code produced by the script module using the CSV file produced by the data module.
The OpenAPI architecture does not require modules to declare anything about their system requirements, nor does it require a glue system to attempt to satisfy the system requirements of a module. This is done deliberately in order to keep the specification of modules and the creation of glue systems as simple as possible. However, it means that there is no guarantee that a glue system can run a particular module.
As an example, consider the script module from the CPI pipeline.
The language of this module is R, so we require that R is
installed in order to run the module. Furthermore, the source of
the module contains calls to load the 'httr' and 'XML' packages
for R, so we further require those packages to be installed with
R. Finally, those R packages require installing libraries such as
libxml2and libcurl.
How can we ensure that those software packages are available
for the glue system to run this module?
From version 0.5 of the OpenAPI architecture, it is possible to specify a <host> element within an OpenAPI module. Currently, that can include either a <vagrant> element to describe a running Vagrant virtual machine, or it can include a <docker> element to describe a Docker image. If a host is specified for a module then the glue system executes the module source on that host, rather than on the machine where the glue system is running. This allows us to create virtual environments that are known to satisfy the system requirements of a module.
The CPI pipeline has been modified so that the script module contains a <host> element like this ...
The Docker image pmur002/r-xml
creates a Debian container with R and the packages 'httr' and 'XML installed
(it is based on rocker/r-base,
which in turn is based on
debian:testing).
This is an environment that has all of the system requirements
to run the CPI script module.
Version 0.5 of 'conduit' will respond to that <host> element
by creating a Docker container from the image pmur002/r-xml and
executing the module source on that container, which will ensure that
the module will run.
The Docker images are publicly available on Docker Hub and Docker will automatically download the images if they have not previously been downloaded.
Similar modifications have been made to the other modules in the CPI
pipeline so that the
data module
runs on a rocker/r-base host and the
plot module
runs on a pmur002/r-zoo host (R plus the 'zoo' package).
Altogether these changes mean that we can be sure that the CPI
pipeline will run because each module is being run within a virtual
environment that is known to provide all of the system requirements
for the module.
In order to run the improved CPI pipeline, we still need a glue system, as provided by the 'conduit' package for R. This means we need to install R and the 'conduit' package within R. Furthermore, the host information in the improved CPI pipeline means that we also need to install Docker, to support the creation of Docker containers.
These requirements represent a significant obstacle for a lay user who might want to run the CPI pipeline. However, there is no need to run an OpenAPI pipeline locally. This section describes the construction of a simple web interface for an OpenAPI glue system, which allows a lay user to run a pipeline on a remote server, thereby avoiding the need to locally install R or 'conduit' or any software to support virtual environments for running modules with hosts.
There are two aims for this section: to provide a concrete demonstration of a simple web interface for 'conduit' (an improvement on the vague statement from the previous report that "it should not be difficult to build a simpler interface for a glue system"); and to provide sufficient information about the set up of the simple web interface so that others can create the interface to try out the improved CPI pipeline for themselves.
The interface is a simple web form, consisting of a selection menu to choose a pipeline, and a button to run the selected pipeline (see the image below).
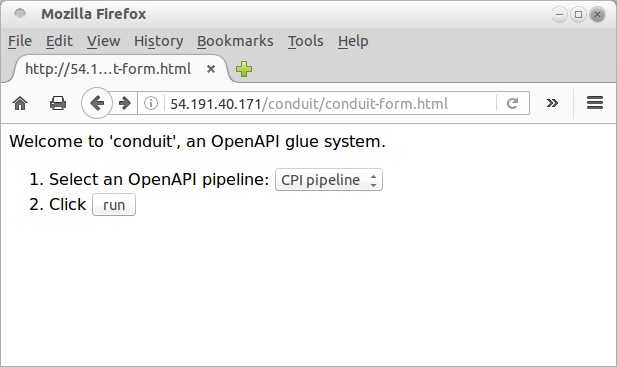
The selection menu in this demonstration only has one pipeline on it, the CPI pipeline, but is representative of a mechanism for selecting from a range of OpenAPI pipelines.
When the "run" button is clicked, the selected pipeline is sent to a simple PHP script that starts R, loads 'conduit', loads the pipeline, and runs the pipeline. This can take a little while the first time because 'conduit', via Docker, has to download the Docker images for the individual modules.
The result of a run is a web page similar to the original form, with an extra item that allows the user to download the result of the run (see the image below).
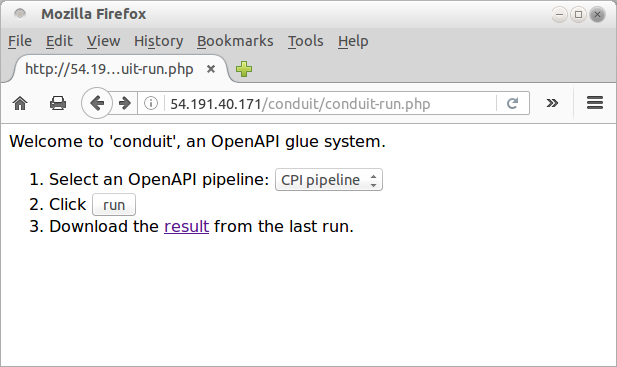
The result is a tar ball containing
a number of resources from the run, including the output from
all modules within the pipeline. The CPI plot that we are most
interested in from running the improved CPI pipeline
is in cpi/plot/cpi.svg within the tar ball (the plot is
shown below).

The web interface requires a web server host that can run 'conduit'. This section provides information about an appropriate web server: an Ubuntu server, with Docker, R, 'conduit', Apache, and PHP installed.
At the time of writing, an Amazon EC2 instance was available at the
IP address: 54.191.40.171
The simple web interface is accessible on that instance via
http://54.191.40.171/conduit/conduit-form.html
At some point, that instance will have to come down as it will eventually cost money to keep it running (plus it is too vulnerable to leave up forever).
At the time of writing, a snapshot of the EC2 instance was also available
as a public Amazon Machine Image (AMI) named
ubuntu-docker-R-conduit-apache-php-ami-1461791903
(a.k.a. ami-15738375).
Anyone with an Amazon Web Services (AWS) account should be
able to spin up a new EC2 instance from that AMI.
An extra complication is that the EC2 instance created from this AMI needs to be associated with a security group that has a rule allowing inbound HTTP traffic.
Unfortunately, at some point that AMI will have to come down too because it costs to store the snapshot on AWS.
The AMI was generated using a Packer template. Once the EC2 instance and the AMI have been taken down, this template can be used to quickly generate a new AMI. Creating an AMI from this template requires installing Packer, plus having an AWS account, plus having an AWS key pair.
This report has demonstrated the use of <host> elements in OpenAPI modules, which allow us to satisfy system requirements for modules by specifying a virtual environment for a module that meets all of the system requirements of the module. We have also demonstrated a simple web interface for the 'conduit' glue system that makes running an OpenAPI pipeline as simple as selecting a pipeline from a menu and clicking a "run" button.
Compared to the original CPI pipeline a significant amount of extra work has been necessary to satisfy module system requirements and to create a user-friendly web interface. However, the good news is that most of that work has been independent of and orthogonal to the original pipeline. We did add <host> elements to the OpenAPI modules, but the creation of the appropriate Docker images is a separate task from creating modules. The creation of the web interface makes use of technologies that are completely independent from the 'conduit' glue system. This is an important feature of the OpenAPI architecture. The intention is to create a greater "attack surface" for a problem; to create more places where individuals can make a independent contributions to an overall solution (and each contribution has the potential to be reused elsewhere).
Another feature of the improved CPI pipeline is that all of the resources involved in the pipeline are publicly available on the internet and the resources are distributed across multiple sites (see the diagram below). Having publicly available resources is important for transparency and facilitates reuse. Having distributed resources means that resources are automatically drawn together when a pipeline is run, rather than having to be manually gathered prior to running a pipeline.

An OpenAPI pipeline is similar to a "workflow" in a system like KNIME or Galaxy. What this example demonstrates is that the emphasis for OpenAPI is on the creation of new modules rather than on the use of existing modules and the emphasis is on connecting distributed resources rather than subsuming resources within a workflow system.
An OpenAPI pipeline is absolutely not an efficient way to solve a problem. The first time that the improved CPI pipeline is run on a fresh EC2 instance, it will take several minutes to complete as several gigabytes of Docker images are downloaded. Even subsequent runs are seriously sub-optimal because each module is run not only in its own R session, but within its own Docker container. However, the OpenAPI architecture is focused on allowing a solution to be constructed from small, independent, reusable components and is prepared to sacrifice efficiency to achieve that goal.
In addition to ignoring efficiency, the OpenAPI architecture has not been concerned with security issues either. Running an OpenAPI pipeline that contains modules from unknown sources (which contain source code from unknown sources) is essentially allowing arbitrary code to execute on your machine. Furthermore, the provisioning scripts in this report that create the AMI for the simple web interface to 'conduit' create a server with some serious vulnerabilities. Running arbitrary OpenAPI pipelines on a machine that you care about, or setting up the simple web interface on a machine that you care about, is not recommended.
Finally,
the claim that virtual environments, like Docker images, "guarantee"
to satisfy system requirements for a module is overstating the case
a little.
For example, the rocker/r-base image will change over
time because it will track both the latest Debian and the latest R versions,
which means that, even though the image works at the time of writing,
there is no guarantee that it will continue to work in the future.
More effort could be made to produce images that are more frozen and
will at least change less over time.
While this improvement to the CPI pipeline has resolved some of the issues identified with the original CPI pipeline, it has also raised new areas for future work.
One issue is the task of finding and filtering OpenAPI pipelines and modules. The aim is to make it very easy to create OpenAPI modules and pipelines and a consequence of that would be a proliferation of modules and pipelines. Some sort of public repository with search facilities, plus some sort of mechanism for tagging modules and pipelines, would be required to assist users with identifying and filtering useful components from a large pool.
Another issue is how to handle the results of running a pipeline. A tar ball of resources is not the most convenient end product for a lay user, so it would be useful to create a "pipeline result explorer" tool to assist with accessing different parts of a pipeline result.
This report follows on from a previous report on an OpenAPI pipeline for CPI data. The purpose of the pipeline is to generate a plot of price changes over time broken down into different areas of spending.
This document demonstrates how to add <host> information to an OpenAPI module so that the module source is run within an environment that is known to satisfy the necessary system requirements. A simple web use interface is also provided to show that running an OpenAPI pipeline can be turned into a simple one-click task. The system does not work perfectly, but the development of the OpenAPI architecture is ongoing.
The examples and discussion in this document relate to version 0.5 of the 'conduit' package.
This report was generated on Ubuntu 14.04 64-bit running R 3.2.3.

An Improved Pipeline for CPI Data
by Paul
Murrell is licensed under a Creative
Commons Attribution 4.0 International License.