Publish for Pleasure
Embracing modern tools for
research publications
Paul Murrell
The University of Auckland
This talk is about how I am currently creating research publications and why I think the process and tools that I use are absolutely genius.
Disclaimer
- My primary research output is open source software
- Most of my publications have only one or two authors
- My research area involves computer technologies
- I like experimenting with computer technologies
I acknowledge that not everyone will have the technical background or interest or freedom to indulge in these technologies.
Notation
Document (noun):
a computer file that contains text that you have written.
http://www.merriam-webster.com/dictionary/document
Document (verb):
support or accompany with documentation.
https://en.oxforddictionaries.com/definition/document
I will use the word "document" to describe the piece of work that I create to document my research. This is instead of more loaded words like report (which implies something less formal or worthy) or article (which implies something that must be published in a journal).
Three Things I Care About
- Working Efficiently and Effectively
- Open Access and Sharing
- Reproducibility and Reuse
I care about not wasting my time and effort. I care about producing something good. I care about everyone being able to access my work and pass it on to others. I care about other people being able to repeat what I did and build on what I did. SIX things I care about!
Part I
Working Efficiently and Effectively
This section covers tools that I use to *create* a document.
Text Files
<h2>Namespaces</h2>
<p>
It is now possible to add SVG content to a web page with
the 'DOM' package.
</p>
<rcode>
page = htmlPage()
appendChild(page, svg, ns="SVG")
</rcode>
<p class="img">
<a href="svgPage.html">
<img style="border: solid 1px" src="svgPage.png"/>
</a>
</p>
This is an example of the sort of text file that I write to create a document. EVERYTHING within the file is text. Images are references to external files. The file consists of content plus a description of the structure of the content (e.g., what is a heading, what is normal text and what is code, ...). This is the same idea as a LaTeX file or a Markdown file, but NOT the same as a Word document.
Text Files
- Easy to create and edit
- Easy to share
- Easy to generate programmatically
- Accurate and expressive
I do not write the final document; I write a text description of the final document, which is processed by various software tools to generate the final document. MANY programs can create and modify text files, so you are not tied to a particular piece of sofware to write your document AND you are not placing any burden on anyone else who wants to view or use your document. It is easy to write code to generate text, which means we can automate the generation of parts of a document. This is the basis for tools like 'Sweave' and 'knitr' in R. Writing text also means that I can write exactly what I mean and I can write complicated things - this becomes more important when I layer XML structure on top ...
XML
<h2>Namespaces</h2>
<p>
It is now possible to add SVG content to a web page with
the 'DOM' package.
</p>
<rcode>
page = htmlPage()
appendChild(page, svg, ns="SVG")
</rcode>
<p class="img">
<a href="svgPage.html">
<img style="border: solid 1px" src="svgPage.png"/>
</a>
</p>
This is an example of the sort of XML that I write to create a document. It is basically HTML, plus some tags that I made up for my own convenience. It is VERY easy to transform this to pure HTML. It is also very easy to transform it to other things (e.g., .Rhtml).
XML
- Structured text
- Open standard
- Good processing tools (XPath, XSLT)
One weakness of text files is that the content can be unstructured, which makes it hard to process. XML solves this problem by using tags to label the structure of the document. Tools like XPath and XLST take advantage of that structure to provide excellent processing tools. This means that we can do more than just process from XML to a publication format (e.g., HTML). We can also process to other formats, e.g., these slides come from an XML file that has been transformed to HTML, but the same XML file also gets transformed to produce speaker notes (and a version for printing as handouts). The fact that XML is an Open Standard means that there are lots of editors and processing tools for working with XML (so a low burden for me and for anyone I want to share or collaborate with). In effect, I create a document by writing code and the computer creates the document from my code. BUT the code that I am writing is in a very simple language. I use XML rather than Markdown because the Markdown does not give me enough control over the final HTML format and because Markdown is limited to generating the final format, whereas XML allows for a much wider range of transformations. The source file for these slides is an XML document that is transformed to HTML for the slides and a .txt file for speaker notes (and a modified HTML document for printing handouts). However, Markdown also works if XML is too much, especially if you have the freedom to select Markdown as part of your workflow and you have the freedom to make use of the final format that Markdown produces for you. LaTeX just does not process as easily as XML and it only easily transforms to PDF.
XPath and XSLT
<xsl:template match="//rcode">
<xsl:comment>begin.rcode
<xsl:apply-templates/>end.rcode</xsl:comment>
</xsl:template>
$ xsltproc replace.xsl document.xml > document.Rhtml
This is an example of the XPath and XSLT code used to transform an XML document (to an .Rhtml file). The XPath bit is '//rcode', which matches ANY rcode element ANYWHERE in the document. The XSLT bit is everything else, which says, IF you get a match to '//rcode', start an XML comment, followed by 'begin.rcode', followed by the content of the rcode element, followed by 'end.rcode', followed by the end of the XML comment. The 'xsltproc' program can be used to apply the XSLT code to the XML document.
XPath and XSLT
<h2>Namespaces</h2>
<p>
It is now possible to add SVG content to a web page with
the 'DOM' package.
</p>
<!--begin.rcode
page <- htmlPage()
appendChild(page, svg, ns="SVG")
end.rcode-->
<p class="img">
<a href="svgPage.html">
<img style="border: solid 1px" src="svgPage.png"/>
</a>
</p>
This is an example of the .Rhtml file that is produced by processing the XML document that I wrote using XPath and XSLT.
Literate Documents
- Mix of text and code chunks
- Output from code automatically inserted
A literate document allows code chunks to be included in the document so that, when the document is processed, the code can be run to generate some of the document content.
Literate Documents

$ Rscript -e 'library(knitr); knit("document.Rhtml")'
The process is now: I write an XML document, then I transform it with XPath and XSLT to a .Rhtml document, then I transform it again with 'knitr' to generate an HTML document.
HTML
<h2>Namespaces</h2>
<p>
It is now possible to add SVG content to a web page with
the 'DOM' package.
</p>
<pre>
page = htmlPage()
appendChild(page, svg, ns="SVG")
</pre>
<pre class="knitr r">
<svg xmlns="http://www.w3.org/2000/svg">
<circle r="50"/>
</svg>
</pre>
<p class="img">
<a href="svgPage.html">
<img style="border: solid 1px" src="svgPage.png"/>
</a>
</p>
This is an example of the HTML that is produced by processing the .Rhtml file that was produced by processing the literate XML document that I wrote.
HTML
- Open standard, text, XML format
- Easy to make a nice-looking document
- Dynamic and interactive
The final document that I produce is an HTML document. HTML does not do typesetting as well as LaTeX does, but you can still produce a nice-looking result (like these slides), usually by making use of someone else's efforts with CSS. HTML is a great publication format because it is an Open Standard, so there are lots of (free) viewers (including web browsers), so no burden is placed on your audience. Oh, and it's still text. Where HTML nails other options (like PDF) is that it is easy to produce dynamic and interactive effects in HTML. HTML is also text and (informal) XML, so inherits all of their nice editing and processing properties. For example, suppose that the tool I used to generate the final HTML document (from my XML document) does not produce EXACTLY what I want; with HTML, I can easily tweak the final result with further processing (much more easily than I could if I had generated a PDF document as my final document). The relevance of HTML as a publication format is demonstrated by the fact that traditional publishers now offer HTML versions of articles online. Some web browsers now have "native" support for viewing PDFs, but not as part of a web page. PDF is not a web format.
HTML
This is an example of an HTML report with an interactive feature: click on the plus to toggle visibility of the code chunks.
SVG
- Vector graphics format
- Integrates with HTML
- Open standard, text, XML format
- Dynamic and interactive
If the pubication format is HTML, then the best format for images is SVG. It is vector (rather than raster), so it looks good at any size, it is an Open Standard so there is lots of software support (all browsers now have native support), PLUS it is XML with all the benefits previously mentioned about structured text. It is also easy to add dynamic and interactive features to an SVG image, which is handy if you are writing a document that describes the creation of dynamic and interactive statistical graphics.
SVG
This is an example of an SVG image (within an HTML document) with an interactive feature: drag the blue rectangle to scroll the window shown in the large plot.
Part I Summary
- The document that I write is an XML document
- The document that I write is a literate document
- The document that I write is processed using XPath and XSLT and 'knitr' to a final HTML document
- Figures are SVG documents
- All documents are text documents
This process is similar to the R Markdown workflow that we have our 20x students use (right?), EXCEPT that I am working at a lower level, so it is more flexible, and I understand more about what is happening, and I have more of a focus on HTML as the final document format and SVG as the graphics format.
Part II
Open Access and Sharing
Having created a document using efficient and effective tools, we now turn to the issue of disseminating the document. The tools in this section focus on making it as efficient as possible for others to access and make use of my work.
Electronic distribution
- Electronic format
- Paperless
- Cheap
- Dynamic and interactive
- Colour for free
- The Journal of Statistical Software (JSS) and the R Journal are ONLY available electronically
Electronic distribution implies BOTH an electronic format (rather than hard copy) AND availability on the world wide web. The best way (the only sensible way) to publish a document is in electronic format (rather than print). Copies are (virtually) free, copying is fast and *exact*, and we gain features like colour and interactivity. It is not controversial to claim that an electronic format is good, but how many of you are still preparing documents for print (e.g., PDFs in A4 page format) ? I enjoy writing a document with the screen as my main format (e.g., freely using colour and interactive content). It is possible to format HTML nicely for print, but the screen format is now the primary concern. JSS was originally aiming for HTML, but backslid to LaTeX/PDF.
Electronic distribution
- Distributed on the Web
- Fast
- Accessible by anyone from anywhere
- Discoverable (by search engine)
- Visible (by blog aggregator, social media)
Distribution of an electronic document via the web means that the publication can be accessed from virtually anywhere virtually instantly. Distribution on the web can be just a matter of placing material on a public web server, but existing search engines and social media can further increase the visibility and discoverability of the material. People care about these things - the web gives them to us for free. Again, it is not crazy to suggest that putting a document on the web is good, but how many of you are writing for the web (e.g., producing HTML documents or interactive SVGs) ? I enjoy writing documents for the web.
Creative Commons
- Copyright licences with not all rights reserved
- Creative Commons Attribution (CC BY)
- Explicitly allows others to copy and modify
- JSS and the R Journal require CC BY
- Other journals make you pay for the privilege
If you are conducting publicy funded research, the results have already been paid for. It makes sense to provide the results as openly as possible. The CC BY licence fits this situation perfectly.
Traditional Transfer of Copyright
... the owner of the copyright in this work, hereby grants and assigns exclusively to ASA, IMS, and IFNA all rights in and to the above manuscript now or hereafter protected by the copyright laws of the United States and all foreign countries, including, but not limited to,the right to prepare derivative works and the right to publish the manuscript in computer-based formats.
(emphasis mine)
In the traditional publishing model the copyright is signed over to the publisher and they limit access in order to charge for access (business model). Note that the transfer of copyright is quite substantial and quite persistent. My children are unlikely to live long enough to see my article enter the public domain. This is not good. I enjoy publishing documents with a CC BY licence.
Creative Commons
You are free to:
Share — copy and redistribute the material in any medium or format
Adapt — remix, transform, and build upon the material
for any purpose, even commercially.
Under the following terms:
Attribution — You must give appropriate credit ...
No additional restrictions — You may not apply legal
terms or technological measures that legally restrict others from
doing anything the license permits.
(emphasis mine)
Contrast the expressions used here with those used in the traditional publisher contract. These words are compatible with sharing and unrestricted reuse. This is good.
DIY Publishing
- Creating a document can be self-sufficient
- Distributing a document can be self-sufficient
- No need for a middle man
- Choose your own publication format (HTML)
- Choose your own licence (CC BY)
- Choose when to publish (NOW)
- No need for volumes or issues
Publishing outside of a traditional journal makes it possible to really take advantage of the available tools. We are not restricted by journal format rules, we are not hindered by the slow peer review process, we are not restricted by journal copyright assertions. If we no longer need to publish through a journal, we can think about escaping other artificial constraints like bundling articles into volumes or issues. A publication can be published on its own. For example, the Journal of Statistical Software ONLY publishes in electronic format and it publishes individual articles. JSS and R Journal still dictate the format (PDF) and still have a slow review process I withdrew an article from JSS after 2 years in the review process because the software had changed so much that the article had essentially become a bunch of lies!
DIY Publishing
http://stattech.wordpress.fos.auckland.ac.nz/
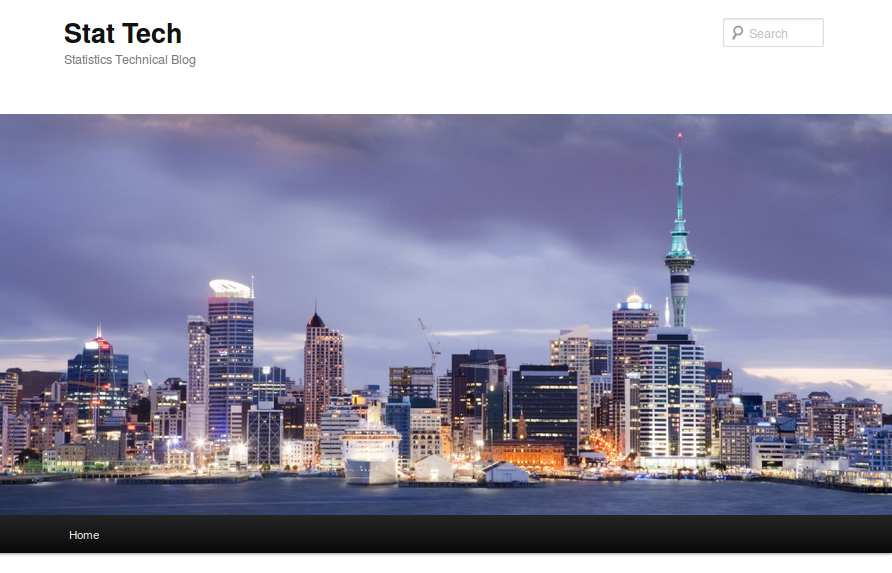
If you don't want to run your own web server, the department has a Technical Blog where you can easily publish a document. My latest publication is a technical report published on the department's technical blog. I now have authored (or co-authored) 29 publications on the technical blog. DIY publishing allows for a greater variety of publishing models - rather than a one-size-fits-all journal article, we can have shorter or longer pieces of work. Smaller publications allows for documenting smaller pieces of work, such as student projects. More than 10 of my publications on the technical blog are based on student projects (BScHons, Masters, or Summer Scholarship). There are several more that are single-authored student publications (PhD or research assistant). I could also have used something like ArXiv, though that is still focused on preprints of print articles.
Research Repositories
- Persistent storage of research results
- Figshare
- UoA Library ResearchSpace
In addition to making a document available *now*, we should be concerned with the document *remaining* available. There are independent services like figshare. These promise to provide persistent storage and increase visibility for works. UoA has its own figshare portal. UoA library has ResearchSpace. This has the advantage of having a reasonable chance of existing for as long as UoA exists.
figshare
https://auckland.figshare.com/
figshare
https://figshare.com/articles/_DOM_Version_0_2/3842793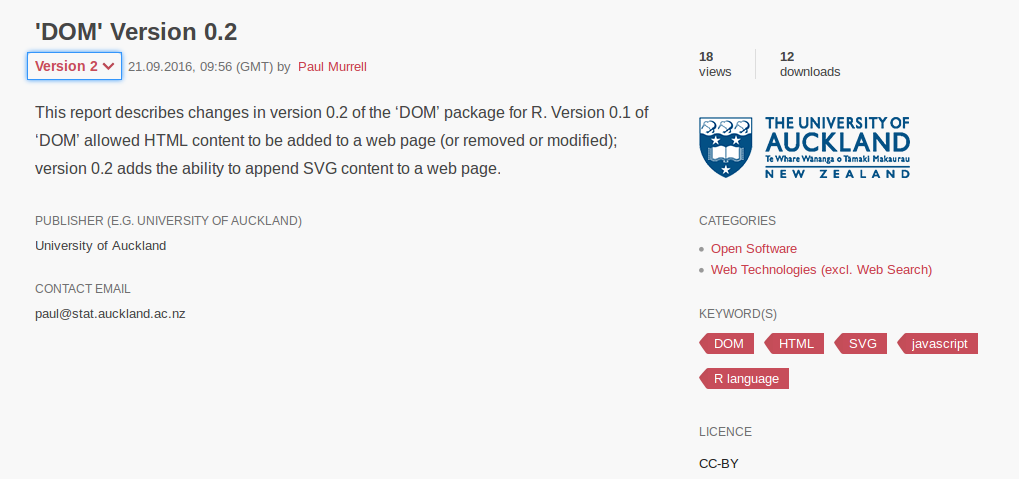
Research Space
https://researchspace.auckland.ac.nz/
Research Space
https://researchoutputs.auckland.ac.nz/repository.html?pub=541132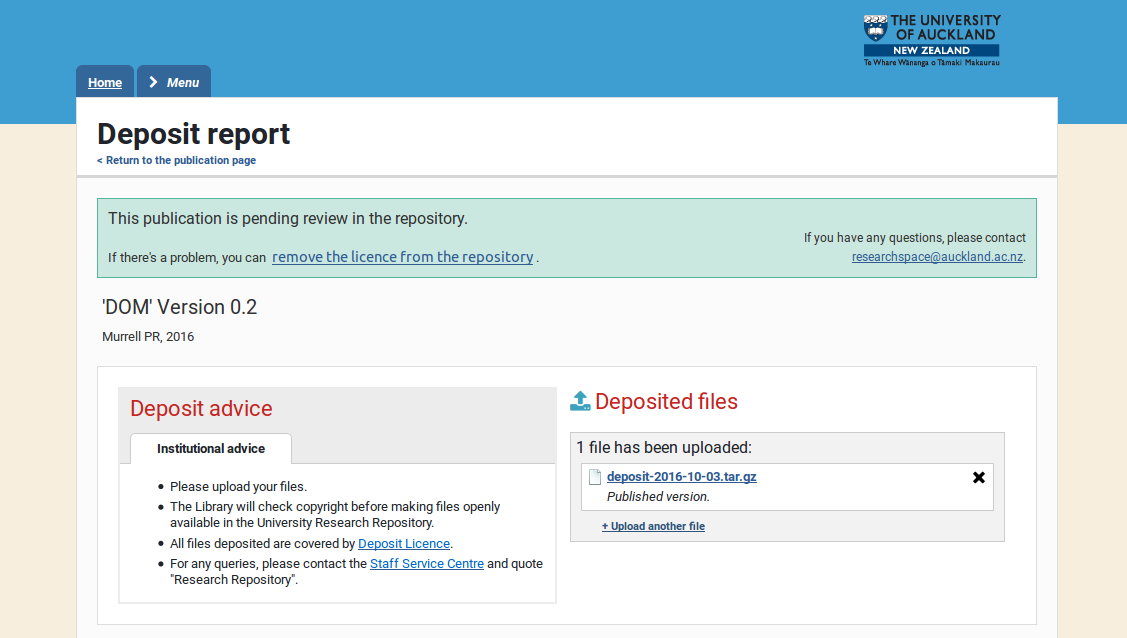
Part II Summary
- An electronic document is easy and cheap to distribute
- A document on the web is easy to find and access
- A CC BY licence makes it easy to copy, modify, and share
- A self-published document is cheaper and faster to publish
- A document in a research repository is persistent
Part III
Reproducibility and Reuse
We have already talked about literate documents and tools like 'knitr', which make it easy to create a document that can be reproduced by someone other than the original author. This part of the talk describes some other important pieces that we can share. The focus is still on others having access to my work, but we have moved on to allowing others to do more than just *view* the work.
Supplementary Material
In addition to the final HTML document, I also distribute ...
- The software described in the document (as an R package)
- My original XML document
- XSL files and Makefile to convert from XML to Rhtml to HTML
- Dockerfile describing a machine image that can be used to generate the report
EVERYTHING needed to reproduce the report is available online under a permissive licence. The open standard text formats and permissive licences also make it easy to create new work based on these materials.
Supplementary Material
This shows the list of materials provided for one of my recent publications. A lot of these materials have nice features like the fact that they are all text files. However, even with all of these resources, there is no guarantee that someone else has all of the tools available to work with them (I work on Linux). This is where Docker comes in ...
Docker
Dockerfile
# Base image
FROM ubuntu:16.04
MAINTAINER Paul Murrell <paul@stat.auckland.ac.nz>
# Install additional software
RUN apt-get update && apt-get install -y \
xsltproc \
r-base=3.3.1* \
wget \
libxml2-dev \
libcurl4-openssl-dev \
libssl-dev
A Dockerfile is a text description of a computer (operating system and installed programs); a sort of virtual machine.
Docker
Docker image
docker build -t pmur002/dom-v0.2 ./Dockerfile
docker run pmur002/dom-v0.2 make DOM-v0.2.html
docker login -u=pmur002
docker push pmur002/dom-v0.2
We can build a Docker image from a Dockerfile, then we can run that image (virtual machine) and run a command within the virtual machine. We can also publish the Docker image on the internet (DockerHub) so that others can easily access and reuse the virtual machine (e.g., to reproduce the research document).
Docker Hub
https://hub.docker.com/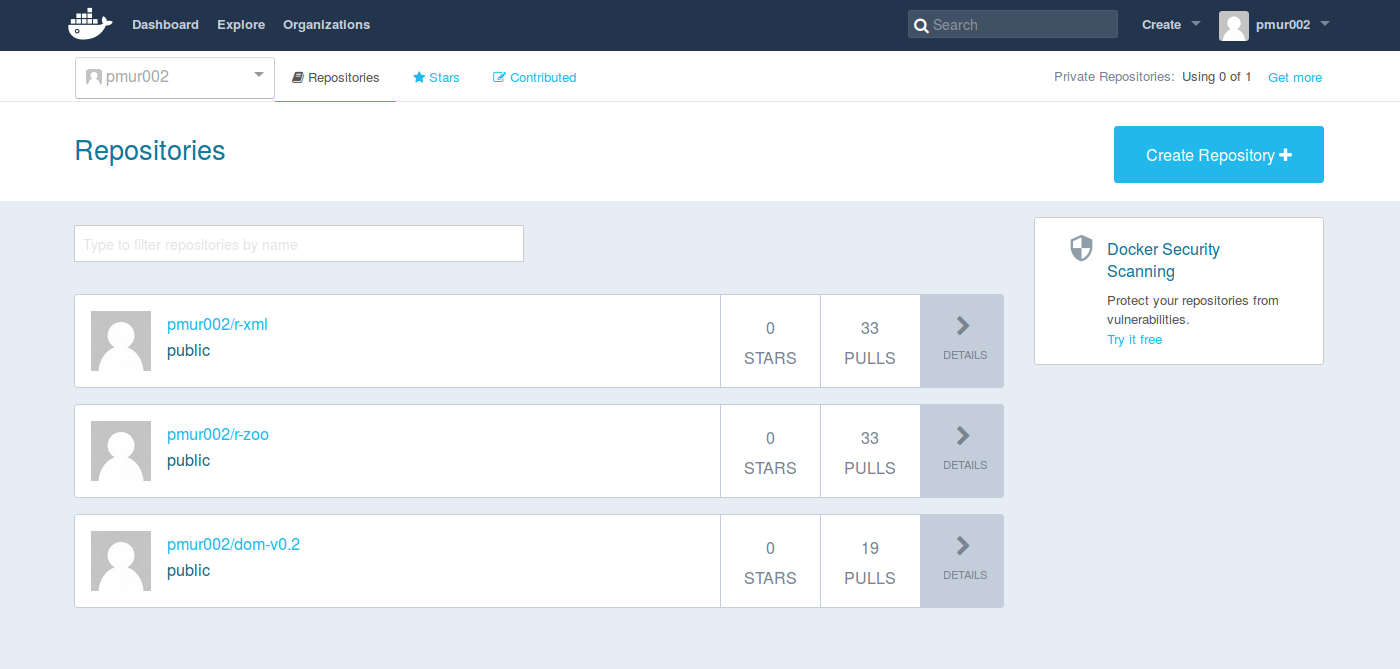
Part III Summary
- Distributing supplementary material with a document (with permissive licences) makes it easy for others to reproduce and reuse research work
- R packages make it easy to share research software
- Text files make it easy to share resources AND instructions on how to reproduce a document
- Docker makes it easy to describe and share a computational environment for reproducing a document
Part IV
Recognition
This section is about "recognition" in the sense of avoiding confusion and ambiguity with regards to who wrote a document. There are a couple of slides at the end that briefly address "recognition" in the sense of being rewarded for work (with fame and professional advancementXS).
ORCID
https://myorcid.auckland.ac.nz/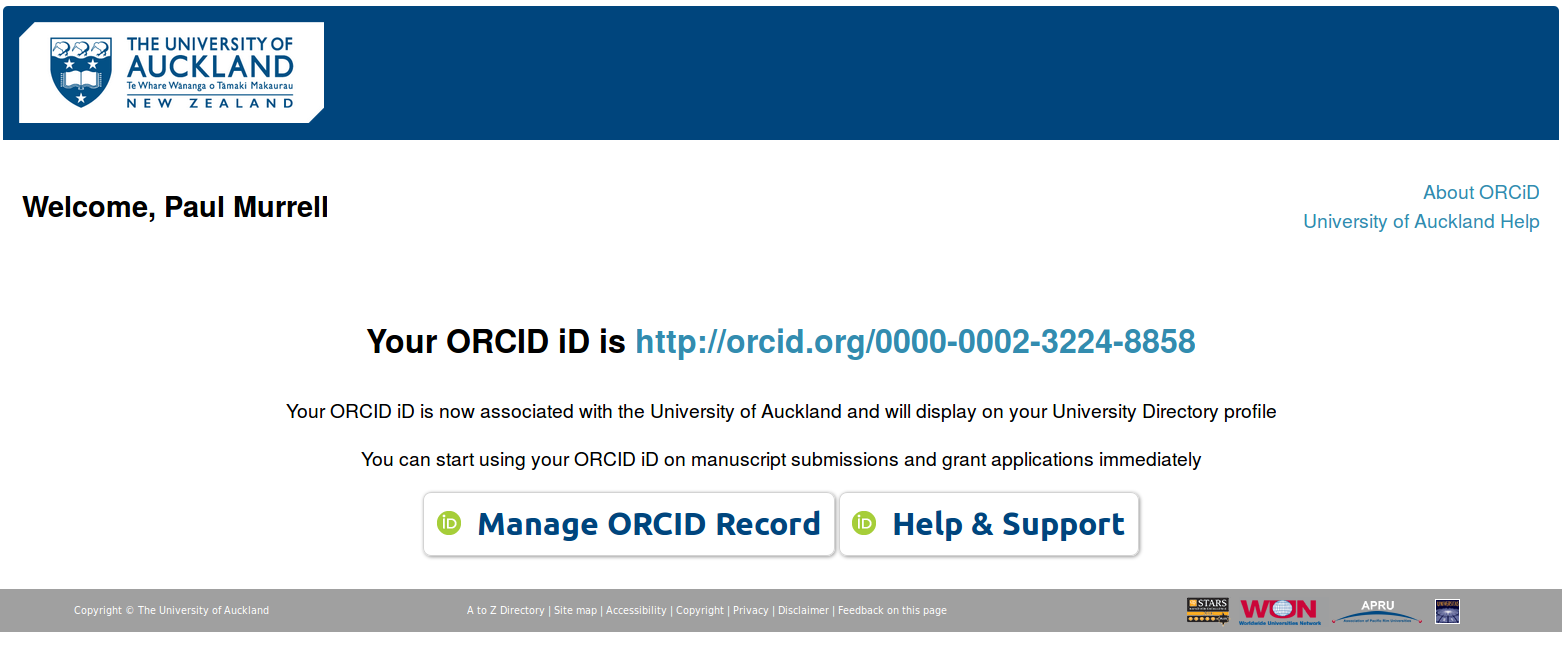
ORCiD provides a unique identifier for every researcher, so that I cannot be confused with someone else, just in case there is another Paul Murrell in the world who happens to specialise in producing slow statistical graphics software.
Summary
Adopting modern tools leads to self-sufficiency,
which leads to ...
- Open licences
- Great formats
- Instant publication
- Distribution anywhere/everywhere
- Distributing anything/everything
- Experimentation
Technology is allowing us to do more and more of the publishing process ourselves. DIY publishing means greater access to and freedom to explore these technologies. Another way to look at it is that these technologies allow you to work (on your publication) more like a programmer - yet another reason for computing to have a greater presence in our curriculum!
Summary #2
If you are a publicly-funded researcher
and your primary goal is to disseminate
the results of your work
as efficiently
and effectively and rapidly
and widely and persistently
and reproducibly as possible
(and you have a weakness/affinity for computer tech)
there are some great tools available to
help you to
achieve your goal.
My *primary* concern is publishing and sharing my work. The problem of *measuring* my worth is *secondary*. I believe that is the correct order. Recently, I have been conducting small pieces of work, consisting of adding new features to an R package. Within a very short time, I can develop the R package, make it available, write a document describing the changes and demonstrating their use (if only as a reminder to myself of what I have done!), and make that document available. The entire research cycle can occur within the space of a couple of weeks.
Acknowledgements
- Hammer image by Jamie Dickinson from the Noun Project
Technology Roll of Honour
- HTML and SVG
- XML, XPath and XSLT
- The World Wide Web
- R and 'knitr'
- Creative Commons
- Linux, emacs, xsltproc, and make
- Docker
Finis

Publish for Pleasure
by Paul
Murrell is licensed under a Creative
Commons Attribution 4.0 International License.
Peer review
- You do not need an editor to ask someone for feedback
- You can ask more than 2 people for feedback
-
Review can happen post-publication
(this is what happens with software)
If you want independent peer review, there are already services offering that (for a price), e.g., Rubriq.
Metrics
- Citations can still happen
- New sorts of metrics
- Number of downloads
- Google PageRank
- Number of links, likes, and retweets
Once it becomes easy to publish, number of publications is less meaningful. The emphasis is more on quality, as measured by things like citations, or other measures of how much your work is used and valued by others.
