The full stop character matches any single character of any sort (apart from a newline).
For example, the regular expression ".at" means: any letter, followed by the letter `a', followed by the letter `t'.
".at" 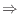 The cat
sat
on the mat
.
The cat
sat
on the mat
.
For example, the regular expression ".at" means: any letter, followed by the letter `a', followed by the letter `t'.
For example, the regular expression "[Tt]he" means: an uppercase `T' or a lowercase `t', followed by the letter `h', followed by the letter `e'.
For example, the regular expression "[a-z]at" means: any (English) lowercase letter, followed by the letter `a', followed by the letter `t'.
For example, the regular expression "[^c]at" means: any letter except `c', followed by the letter `a', followed by the letter `t'.
For example, the regular expression "at[.]" means: the letter `a', followed by the letter `t', followed by a full stop.
In POSIX regular expressions, common character ranges can be specified using special character sequences of the form [:keyword:] (see Table 11.1). The advantage of this approach is that the regular expression will work in different languages. For example, [a-z] will not capture all characters in languages that include accented characters, but [[:alpha:]] will.
For example, the regular expression "[[:lower:]]at" means: any lowercase letter in any language, followed by the letter `a', followed by the letter `t'.
Anchors do not match characters. Instead, they match zero-length features of a piece of text, such as the start and end of the text.
For example, the regular expression "^[Tt]he" means: at the start of the text an uppercase `T' or a lowercase `t', followed by the letter `h', followed by the letter `e'.
For example, the regular expression "at.$" means: the letter `a', followed by the letter `t', followed by any character, at the end of the text.
For example, the regular expression "cat|sat" means: the letter `c', followed by the letter `a', followed by the letter `t', or the letter `s', followed by the letter `a', followed by the letter `t'.
Three metacharacters are used to specify how many times a subpattern can repeat. The repetition relates to the subpattern that immediately precedes the metacharacter in the regular expression. By default, this is just the previous character, but if the preceding character is a closing square bracket or a closing parenthesis then the modifier relates to the entire character set or the entire subpattern within the parentheses (see Section 11.2.5 below).
For example, the regular expression "at[.]?" means: the letter `a', followed by the letter `t', optionally followed by a full stop.
For example, the regular expression "[a-z]+" means: any number of (English) lowercase letters in a row.
For example, the regular expression "(c|s)at" means: the letter `c' or the letter `s', followed by the letter `a', followed by the letter `t'.
Grouping is also useful for retaining original portions of text when performing a search-and-replace operation (see Section 11.2.6).
It is possible to refer to previous subpatterns within a regular expression using backreferences.
For example, the regular expression "c(..) s\\1" means: the letter `c', followed by any two letters, followed by a space, followed by the letter `s', followed by whichever two letters followed the letter `c'.
When performing a search-and-replace operation, backreferences may be used to specify that the text matched by a subpattern should be used as part of the replacement text.
For example, in the first replacement below, the literal text `cat' is replaced with the literal text `cot', but in the second example, any three-letter word ending in `at' is replaced by a three-letter word with the original starting letter but ending in `ot'.
> gsub("cat", "cot", text)
[1] "The cot sat on the mat."
|
> gsub("(.)at", "\\1ot", text)
[1] "The cot sot on the mot."
|
Notice that, within an R expression, the backslash character must be escaped as usual, so the replacement text referring to the first subpattern would have to written like this: "\\1".
Some more realistic examples of the use of backreferences are given in Section 9.9.3.
Paul Murrell

This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 New Zealand License.