 |
One of the main problems with plain text formats is that there is no information within the file itself to describe the location of the data values.
One solution to this problem is to provide a recognizable label for each data value within the file.
This section looks at the eXtensible Markup Language, XML, which provides a formal way to provide this sort of labeling or “markup” for data.
Data stored in an XML document is stored as characters, just like in a plain text format, but the information is organized within the file in a much more sophisticated manner.
As a simple example to get us started, Figure 5.13 shows the surface temperature data at the Pacific Pole of Inaccessibility (see Section 1.1) in two different formats: an XML format and the original plain text format.
|
<?xml version="1.0"?>
<temperatures>
<variable>Mean TS from clear sky composite (kelvin)</variable>
<filename>ISCCPMonthly_avg.nc</filename>
<filepath>/usr/local/fer_dsets/data/</filepath>
<subset>48 points (TIME)</subset>
<longitude>123.8W(-123.8)</longitude>
<latitude>48.8S</latitude>
<case date="16-JAN-1994" temperature="278.9" />
<case date="16-FEB-1994" temperature="280" />
<case date="16-MAR-1994" temperature="278.9" />
<case date="16-APR-1994" temperature="278.9" />
<case date="16-MAY-1994" temperature="277.8" />
<case date="16-JUN-1994" temperature="276.1" />
...
</temperatures>
VARIABLE : Mean TS from clear sky composite (kelvin)
FILENAME : ISCCPMonthly_avg.nc
FILEPATH : /usr/local/fer_data/data/
SUBSET : 48 points (TIME)
LONGITUDE: 123.8W(-123.8)
LATITUDE : 48.8S
123.8W
23
16-JAN-1994 00 / 1: 278.9
16-FEB-1994 00 / 2: 280.0
16-MAR-1994 00 / 3: 278.9
16-APR-1994 00 / 4: 278.9
16-MAY-1994 00 / 5: 277.8
16-JUN-1994 00 / 6: 276.1
...
|
The major difference between these two storage formats is that, in the XML version, every single data value is distinctly labeled. This means that, for example, even without any background explanation of this data set, we could easily identify the “temperature” values within the XML file. By contrast, the same task would be impossible with the plain text format, unless additional information is provided about the data set and the arrangement of the values within the file. Importantly, the XML format allows a computer to perform this task completely automatically because it could detect the values with a label of temperature within the XML file.
One fundamental similarity between these formats is that they are both just text. This is an important and beneficial property of XML; we can read it and manipulate it without any special skills or any specialized software.
XML is a storage format that is still based on plain text but does not suffer from many of the problems of plain text files because it adds flexibility, rigor, and standardization.
Many of the benefits of XML arise from the fact that it is a computer language. When we store a data set in XML format, we are writing computer code that expresses the data values to the computer. This is a huge step beyond free-form plain text files because we are able to communicate much more about the data set to the computer. However, the cost is that we need to learn the rules of XML so that we can communicate the data correctly.
In the next few sections, we will focus on the details of XML. In Section 5.5.1, we will look briefly at the syntax rules of XML, which will allow us to store data correctly in an XML format. We will see that there is a great degree of choice when using XML to store a data set, so in Sections 5.5.2 and 5.5.3, we will discuss some ideas about how to store data sensibly in an XML format--some uses of XML are better than others. In Section 5.5.5 we will return to a more general discussion of how XML formats compare to other storage formats.
The information in this section will be useful whether we are called upon to create an XML document ourselves or whether we just have to work with a data set that someone else has chosen to store in an XML format.
As we saw in Chapter 2, the first thing we need to know about a computer language are the syntax rules, so that we can write code that is correct.
We will use the XML format for the Point Nemo temperature data (Figure 5.13) to demonstrate some of the basic rules of XML syntax.
The XML format of the data consists of two parts: XML markup and the actual data itself. For example, the information about the latitude at which these data were recorded is stored within XML tags, <latitude> and </latitude>. The combination of tags and content is together described as an XML element.
<latitude>48.8S</latitude>
| element: | <latitude>48.8S</latitude> |
| start tag: | <latitude>48.8S</latitude> |
| data value: | <latitude> 48.8S</latitude> |
| end tag: | <latitude>48.8S </latitude> |
Each temperature measurement in the XML file is contained within a case element, with the date and temperature data recorded as attributes of the element. The values of attributes must be contained within double-quotes.
<case date="16-JAN-1994"
temperature="278.9" />
| element name: | < case date="16-JAN-1994" |
| attribute name: | <case date="16-JAN-1994" |
| attribute value: | <case date=" 16-JAN-1994" |
| attribute name: | temperature="278.9" /> |
| attribute value: | temperature=" 278.9" /> |
This should look very familiar because these are exactly the same notions of elements and attributes that we saw in HTML documents in Chapter 2. However, there are some important differences between XML syntax and HTML syntax. For example, XML is case-sensitive so the names in the start and end tags for an element must match exactly. Some other differences are detailed below.
The first line of an XML document must be a declaration that the file is an XML document and which version of XML is being used.
<?xml version="1.0"?>
The declaration can also include information about the encoding of the XML document (see Section 5.2.7), which is important for any software that needs to read the document.
<?xml version="1.0" encoding="UTF-8"?>
Unlike HTML, where there is a fixed set of allowed elements, an XML document can include elements with any name whatsoever, as long as the elements are all nested cleanly and there is only one outer element, called the root element, that contains all other elements in the document.
In the example XML document in Figure 5.13, there is a single temperatures element, with all other elements, e.g., variable and case elements, nested within that.
Elements can be empty, which means that they consist only of a start tag (no content and no end tag), but these empty elements must end with />, rather than the normal >. The code below shows an example of an empty case element.
<case date="16-JAN-1994" temperature="278.9" />
Although it is possible to use any element and attribute names in an XML document, in practice, data sets that are to be shared will adhere to an agreed-upon set of elements. We will discuss how an XML document can be restricted to a fixed set of elements later on in Section 5.5.3.
Because XML is a computer language, there is a clear structure within the XML code. As discussed in Section 2.4.3, we should write XML code using techniques such as indenting so that the code is easy for people to read and understand.
As with HTML, the characters <, >, and & (among others) are special and must be replaced with special escape sequences, <, >, and & respectively.
These escape sequences can be very inconvenient when storing data values, so it is also possible to mark an entire section of an XML document as “plain text” by placing it within a special CDATA section, within which all characters lose their special meaning.
As an example, shown below is one of the data values that we wanted to store for the clay tablet YBC 7289 in Section 5.1. These represent the markings that are etched into the clay tablet.
| <<|||| <<<<<| <
If we wanted to store this data within an XML document, we would have to escape every one of the < symbols. The following code shows what the data would look like within an XML document.
| <<|||| <<<<<| <
The special CDATA syntax allows us to avoid having to use these escape sequences. The following code shows what the XML code would look like within an XML document within a CDATA section.
<![CDATA[ | <<|||| <<<<<| < ]]>
There are many software packages that can read XML and most of these will report any problems with XML syntax.
The W3C Markup Validation Service5.4 can be used to perform an explicit check on an XML document online. Alternatively, the libxml software library5.5 can be installed on a local computer. This software includes a command-line tool called xmllint for checking XML syntax. For simple use of xmllint, the only thing we need to know is the name of the XML document and where that file is located. Given an XML document called xmlcode.xml, the following command could be entered in a command window or terminal to check the syntax of the XML code in the file.
xmllint xmlcode.xml
There is no general software that “runs” XML code because the code does not really “do” anything. The XML markup is just there to describe a set of data. However, we will see how to retrieve the data from an XML document later in Sections 7.3.1 and 9.7.7.
Although there are syntax rules that any XML document must follow, we still have a great deal of flexibility in how we choose to mark up a particular data set. It is possible to use any element names and any attribute names that we like.
For example, in Figure 5.13, each set of measurements, a date plus a temperature reading, is stored within a case element, using date and temperature attributes. The first set of measurements in this format is repeated below.
<case date="16-JAN-1994" temperature="278.9" />
It would still be correct syntax to store these measurements using different element and attribute names, as in the code below.
<record time="16-JAN-1994" temp="278.9" />
It is important to choose names for elements and attributes that are meaningful, but in terms of XML syntax, there is no single best answer.
When we store a data set as XML, we have to decide which elements and attributes to use to store the data. We also have to consider how elements nest within each other, if at all. In other words, we have to decide upon a design for the XML document.
In this section, we will look at some of these questions and consider some solutions for how to design an XML document.
Even if, in practice, we are not often faced with the prospect of designing an XML format, this discussion will be useful in understanding why an XML document that we encounter has a particular structure. It will also be useful as an introduction to similar design ideas that we will discuss when we get to relational databases in Section 5.6.
The first XML design issue is to make sure that each value within a data set can be clearly identified. In other words, it should be trivial for a computer to extract each individual value. This means that every single value should be either the content of an element or the value of an attribute. The XML document shown in Figure 5.13 demonstrates this idea.
Figure 5.14 shows another possible XML representation of the Pacific Pole of Inaccessibility temperature data.
|
<?xml version="1.0"?>
<temperatures>
<variable>Mean TS from clear sky composite (kelvin)</variable>
<filename>ISCCPMonthly_avg.nc</filename>
<filepath>/usr/local/fer_dsets/data/</filepath>
<subset>93 points (TIME)</subset>
<longitude>123.8W(-123.8)</longitude>
<latitude>48.8S</latitude>
<cases>
16-JAN-1994 278.9
16-FEB-1994 280.0
16-MAR-1994 278.9
16-APR-1994 278.9
16-MAY-1994 277.8
16-JUN-1994 276.1
...
</cases>
</temperatures>
|
In this design, the irregular and one-off metadata values are individually identified within elements or attributes, but the regular and repetitive raw data values are not. This is not ideal from the point of view of labeling every individual data value within the file, but it may be a viable option when the raw data values have a very simple format (e.g., comma-delimited) and the data set is very large, in which case avoiding lengthy tags and attribute names would be a major saving.
The main point is that, as with the selection of element and attribute names, there is no single best markup strategy for all possible situations.
When presented with a data set, the following questions should guide the design of the XML format:
A simple rule of thumb is then to have an element for each object in the data set (and a different type of element for each different type of object) and then have an attribute for each measurement in the data set.
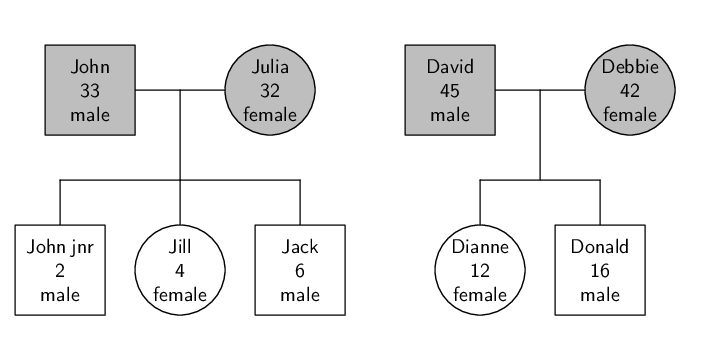
For example, consider the family tree data set in Figure 5.15 (this is a reproduction of Figure 5.3 for convenience). This data set contains demographic information about several related people.
|
In this case, there are obviously measurements taken on people, those measurements being names, ages, and genders. We could distinguish between parent objects and child objects, so we have elements for each of these.
<parent gender="female" name="Julia" age="32" /> <child gender="male" name="Jack" age="6" />
When a data set has a hierarchical structure, an XML document can be designed to store the information more efficiently and more appropriately by nesting elements to avoid repeating values.
For example, there are two distinct families of people, so we could have elements to represent the different families and nest the relevant people within the appropriate family element to represent membership of a family.
<family> <parent gender="male" name="John" age="33" /> <parent gender="female" name="Julia" age="32" /> <child gender="male" name="Jack" age="6" /> <child gender="female" name="Jill" age="4" /> <child gender="male" name="John jnr" age="2" /> </family> <family> <parent gender="male" name="David" age="45" /> <parent gender="female" name="Debbie" age="42" /> <child gender="male" name="Donald" age="16" /> <child gender="female" name="Dianne" age="12" /> </family>
Another decision to make is whether to store data values as the values of attributes of XML elements or as the content of XML elements. For example, when storing the Point Nemo temperature data, we could store the temperature values as attributes of a case element as shown in Figure 5.13 and below.
<case temperature="278.9" />
Alternatively, we could store the temperature values as the content of a temperature element.
<temperature>278.9</temperature>
As demonstrated so far, one simple solution is to store all measurements as the values of attributes. Besides its simplicity, this approach also has the advantage of providing a simple translation between the XML format and a corresponding relational database design. We will return to this point in Section 5.6.7.
However, there is considerable controversy on this point. One standard viewpoint is that the content of elements is data and the attributes are metadata. Another point against storing data in attributes is that it is not always possible or appropriate. For example, a data value may have to be stored as the content of a separate element, rather than as the value of an attribute in the following cases:
Having settled on a particular design for an XML document, we need to be able to write down the design in some way.
We need the design written down so that we can check that an XML document follows the design that we have chosen and so that we can communicate our design to others so that we can share XML documents that have this particular format. In particular, we need to write the design down in such a way that a computer understands the design, so that a computer can check that an XML document obeys the design.
Yes, we need to learn another computer language.
The way that the XML design can be specified is by creating a schema for an XML document, which is a description of the structure of the document. A number of technologies exist for specifying XML schema, but we will focus on the Document Type Definition (DTD) language.
A DTD is a set of rules for an XML document. It contains element declarations that describe which elements are permitted within the XML document, in what order, and how they may be nested within each other. The DTD also contains attribute declarations that describe what attributes an element can have, whether attributes are optional or not, and what sort of values each attribute can have.
Figure 5.16 shows the temperature data at Point Nemo in an XML format (this is a reproduction of part of Figure 5.13 for convenience).
|
<?xml version="1.0"?>
<temperatures>
<variable>Mean TS from clear sky composite (kelvin)</variable>
<filename>ISCCPMonthly_avg.nc</filename>
<filepath>/usr/local/fer_dsets/data/</filepath>
<subset>93 points (TIME)</subset>
<longitude>123.8W(-123.8)</longitude>
<latitude>48.8S</latitude>
<case date="16-JAN-1994" temperature="278.9" />
<case date="16-FEB-1994" temperature="280" />
<case date="16-MAR-1994" temperature="278.9" />
<case date="16-APR-1994" temperature="278.9" />
<case date="16-MAY-1994" temperature="277.8" />
<case date="16-JUN-1994" temperature="276.1" />
...
</temperatures>
|
The structure of this XML document is as follows. There is a single overall temperatures element that contains all other elements. There are several elements containing various sorts of metadata: a variable element containing a description of the variable that has been measured; a filename element and a filepath element containing information about the file from which these data were extracted; and three elements, subset, longitude, and latitude, that together describe the temporal and spatial limits of this data set. Finally, there are a number of case elements that contain the core temperature data; each case element contains a temperature measurement and the date of the measurement as attributes.
A DTD describing this structure is shown in Figure 5.17.
|
<!ELEMENT temperatures (variable,
filename,
filepath,
subset,
longitude,
latitude,
case*)>
<!ELEMENT variable (#PCDATA)>
<!ELEMENT filename (#PCDATA)>
<!ELEMENT filepath (#PCDATA)>
<!ELEMENT subset (#PCDATA)>
<!ELEMENT longitude (#PCDATA)>
<!ELEMENT latitude (#PCDATA)>
<!ELEMENT case EMPTY>
<!ATTLIST case
date ID #REQUIRED
temperature CDATA #IMPLIED>
|
The DTD code consists of two types of declarations. There must be an <!ELEMENT> declaration for each type of element that appears in the XML design and there must be an <!ATTLIST> declaration for every element in the design that has one or more attributes.
The main purpose of the <!ELEMENT> declarations is to specify what is allowed as the content of a particular type of element. The simplest example of an <!ELEMENT> declaration is for case elements (line 14) because they are empty (they have no content), as indicated by the keyword EMPTY. The components of this declaration are shown below.
| keyword: | <! ELEMENT case EMPTY> |
| element name: | <!ELEMENT case EMPTY> |
| keyword: | <!ELEMENT case EMPTY> |
The keywords ELEMENT and EMPTY will be the same for the declaration of any empty element. All that will change is the name of the element.
Most other elements are similarly straightforward because their contents are just text, as indicated by the #PCDATA keyword (lines 8 to 13). These examples demonstrate that the declaration of the content of the element is specified within parentheses. The components of the declaration for the longitude element are shown below.
| keyword: | <! ELEMENT longitude (#PCDATA)> |
| element name: | <!ELEMENT longitude (#PCDATA)> |
| parentheses: | <!ELEMENT longitude (#PCDATA )> |
| element content: | <!ELEMENT longitude ( #PCDATA)> |
The temperatures element is more complex because it can contain other elements. The declaration given in Figure 5.17 (lines 1 to 7) specifies seven elements (separated by commas) that are allowed to be nested within a temperatures element. The order of these elements within the declaration is significant because this order is imposed on the elements in the XML document. The first six elements, variable to latitude, are compulsory because there are no modifiers after the element names; exactly one of each element must occur in the XML document. The case element, by contrast, has an asterisk, *, after it, which means that there can be zero or more case elements in the XML document.
The purpose of the <!ATTLIST> declarations in a DTD is to specify which attributes each element is allowed to have. In this example, only the case elements have attributes, so there is only one <!ATTLIST> declaration (lines 16 to 18). This declaration specifies three things for each attribute: the name of the attribute, what sort of value the attribute can have, and whether the attribute is compulsory or optional. The components of this declaration are shown below.
| keyword: | <! ATTLIST case |
| element name: | <!ATTLIST case |
| attribute name: | date ID #REQUIRED |
| attribute value: | date ID #REQUIRED |
| compulsory attribute: | date ID #REQUIRED |
| attribute name: | temperature CDATA #IMPLIED> |
| attribute value: | temperature CDATA #IMPLIED> |
| optional attribute: | temperature CDATA #IMPLIED> |
The date attribute for case elements is compulsory (#REQUIRED) and the value must be unique (ID). The temperature attribute is optional (#IMPLIED) and, if it occurs, the value can be any text (CDATA).
Section 6.2 describes the syntax and semantics of DTD files in more detail.
The rules given in a DTD are associated with an XML document by adding a Document Type Declaration as the second line of the XML document. This can have one of two forms:
The DRY principle suggests that an external DTD is the most sensible approach because then the same DTD rules can be applied efficiently to many XML documents.
An XML document is said to be well-formed if it obeys the basic rules of XML syntax. If the XML document also obeys the rules given in a DTD, then the document is said to be valid. A valid XML document has the advantage that we can be sure that all of the necessary information for a data set has been included and has the correct structure, and that all data values have the correct sort of value.
The use of a DTD has some shortcomings, such as a lack of support for precisely specifying the data type of attribute values or the contents of elements. For example, it is not possible to specify that an attribute value must be an integer value between 0 and 100. There is also the difficulty that the DTD language is completely different from XML, so there is another technology to learn. XML Schema is an XML-based technology for specifying the design of XML documents that solves both of those problems, but it comes at the cost of much greater complexity. This complexity has led to the development of further technologies that simplify the XML Schema syntax, such as Relax NG.
So far we have discussed designing our own XML schema to store data in an XML document. However, many standard XML schema already exist, so another option is simply to choose one of those instead and create an XML document that conforms to the appropriate standard.
These standards have typically arisen in a particular area of research or business. For example, the Statistical Data and Metadata eXchange (SDMX) format has been developed by several large financial institutions for sharing financial data, and the Data Documentation Initiative (DDI) is aimed at storing metadata for social science data sets.
One downside is that these standards can be quite complex and may require expert assistance and specialized software to work with the appropriate format, but the upside is integration with a larger community of researchers and compatibility with a wider variety of software tools.
We will now consider XML not just as an end in itself, but as one of many possible storage formats. In what ways is the XML format better or worse than other storage options, particularly the typical unstructured plain text format that we saw in Section 5.2?
The core advantage of an XML document is that it is self-describing.
The tags in an XML document provide information about where the data is stored within the document. This is an advantage because it means that humans can find information within the file easily. That is true of any plain text file, but it is especially true of XML files because the tags essentially provide a level of documentation for the human reader. For example, the XML element shown below not only makes it easy to determine that the value 48.8S constitutes a single data value within the file, but it also makes it clear that this value is a north-south geographic location.
<latitude>48.8S</latitude>
The fact that an XML document is self-describing is an even greater advantage from the perspective of the computer. An XML document provides enough information for software to determine how to read the file, without any further human intervention. Look again at the line containing latitude information.
<latitude>48.8S</latitude>
There is enough information for the computer to be able to detect the value 48.8S as a single data value, and the computer can also record the latitude label so that if a human user requests the information on latitude, the computer knows what to provide.
One consequence of this feature that may not be immediately obvious is that it is much easier to modify the structure of data within an XML document compared to a plain text file. The location of information within an XML document is not so much dependent on where it occurs within the file, but where the tags occur within the file. As a trivial example, consider reversing the order of the following lines in the Point Nemo XML file.
<longitude>123.8W(-123.8)</longitude> <latitude>48.8S</latitude>
If the information were stored in the reverse order, as shown below, the task of retrieving the information on latitude would be exactly the same. This can be a huge advantage if larger modifications need to be made to a data set, such as adding an entire new variable.
<latitude>48.8S</latitude> <longitude>123.8W(-123.8)</longitude>
The second main advantage of the XML format is that it
can accommodate complex data structures. Consider the
hierarchical data set in Figure 5.15. Because
XML elements can be nested within each other, this sort of
data set can be stored in a sensible fashion with families
grouped together to make parent-child relations implicit and
avoid repetition of the parent data. The plain text
representation of these data are reproduced from page ![]() below along with a possible XML representation.
below along with a possible XML representation.
John 33 male
Julia 32 female
John Julia Jack 6 male
John Julia Jill 4 female
John Julia John jnr 2 male
David 45 male
Debbie 42 female
David Debbie Donald 16 male
David Debbie Dianne 12 female
<family> <parent gender="male" name="John" age="33" /> <parent gender="female" name="Julia" age="32" /> <child gender="male" name="Jack" age="6" /> <child gender="female" name="Jill" age="4" /> <child gender="male" name="John jnr" age="2" /> </family> <family> <parent gender="male" name="David" age="45" /> <parent gender="female" name="Debbie" age="42" /> <child gender="male" name="Donald" age="16" /> <child gender="female" name="Dianne" age="12" /> </family>
The XML format is superior in the sense that the information about each person is only recorded once. Another advantage is that it would be very easy to represent a wider range of situations using the XML format. For example, if we wanted to allow for a family unit to have a third parent (e.g., a step-parent), that would be straightforward in XML, but it would be much more awkward in the fixed rows-and-columns plain text format.
Another important advantage of the XML format is that it provides some level of checking on the correctness of the data file (a check on the data integrity). First of all, there is the fact that any XML document must obey the rules of XML, which means that we can use a computer to check that an XML document at least has a sensible structure.
If an XML document also has a DTD, then we can perform much more rigid checks on the correctness of the document. If data values are stored as attribute values, it is possible for the DTD to provide checks that the data values themselves are valid. The XML Schema language provides even greater facilities for specifying limits and ranges on data values.
The major disadvantage of XML is that it generates large files. With its being a plain text format, it is not memory efficient to start with, and with all of the additional tags around the actual data, files can become extremely large. In many cases, the tags can take up more room than the actual data!
These issues can be particularly acute for research data sets, where the structure of the data may be quite straightforward. For example, geographic data sets containing many observations at fixed locations naturally form a 3-dimensional array of values, which can be represented very simply and efficiently in a plain text or binary format. In such cases, having highly repetitive XML tags around all values can be very inefficient indeed.
The verbosity of XML is also a problem for entering data into an XML format. It is just too laborious for a human to enter all of the tags by hand, so, in practice, it is only sensible to have a computer generate XML documents.
It should also be acknowledged that the additional sophistication of XML creates additional costs. Users have to be more educated and the software has to be more complex, which means that fewer software packages are able to cope with data stored as XML.
In summary, the fact that computers can read XML easily and effectively, plus the fact that computers can produce XML rapidly (verbosity is less of an issue for a computer), means that XML is an excellent format for transferring information between different software programs. XML is a good language for computers to use to talk to each other, with the added bonus that humans can still easily eavesdrop on the conversation.
XML consists of elements and attributes, with data values stored as the content of elements or as the values of attributes.
The design of an XML document--the choice of elements and attributes--is important. One approach has an element for each different object that has been measured, with the actual measurements recorded as attributes of the appropriate element.
The DTD language can be used to formally describe the design of an XML document.
The major advantage of XML is that XML documents are self-describing, which means that each data value is unambiguously labeled within the file, so that a computer can find data values without requiring additional information about the file.
Paul Murrell

This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 New Zealand License.