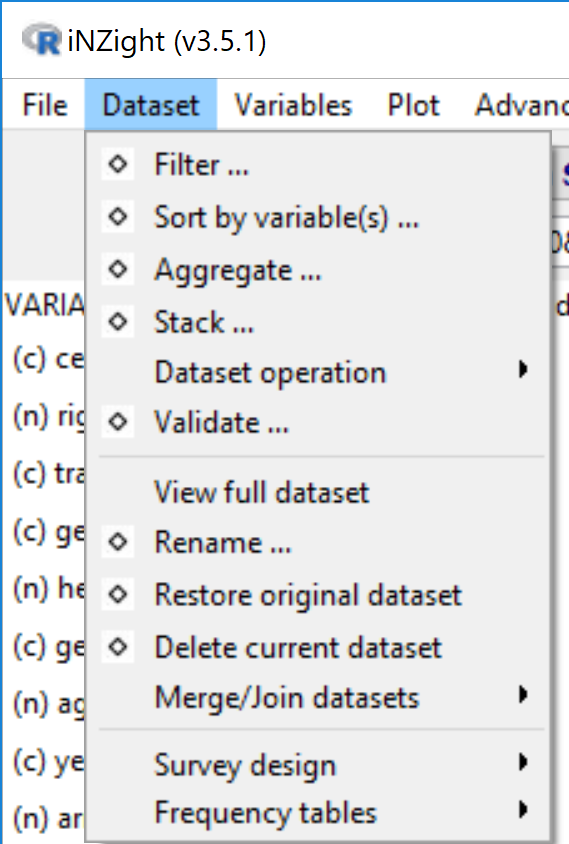
Dataset Menu
(Organise and restructure your data, specify special structures, and filter out unwanted observations)
Contents
-
Filter ... (dataset)
• Levels of a categorical variable
• Numeric condition
• Row number
• Randomly - Sort (dataset) by variable(s) ...
- Aggregate ... (data)
- Stack ... (variables)
- Dataset operations:
• Reshape dataset
- Wide to long
- Long to wide
• Separate column (into) ...
- into several columns
- into several rows
• Unite columns ... - Validate ... (dataset)
- View full dataset
- Rename ... (dataset)
- Restore original dataset
-
Delete current dataset
-
Merge/Join datasets:
• Join datasets (several types of join)
• Append rows -
Survey design (for data from complex survey designs)
• About survey data
• Specify design ...
• Specify replicate design ...
• Post stratify ... (or rake or calibrate)
• Remove design ... - Frequency tables (values plus frequencies data format)
• Expand table
• Specify frequency column
• Remove frequency column
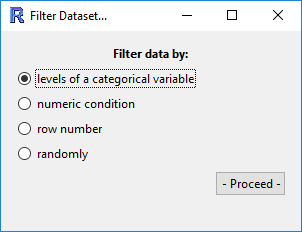
Filter Dataset
This tool provides several methods for filtering the dataset. The window that opens has four options for you to choose from:
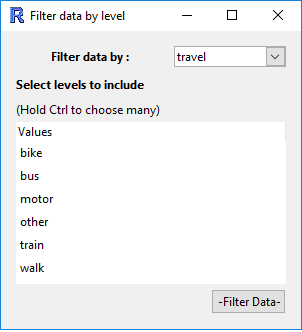
(Filter by) Levels of a categorical variable
After selecting a categorical variable from the drop down box, you can select which levels you want to keep in the data set.
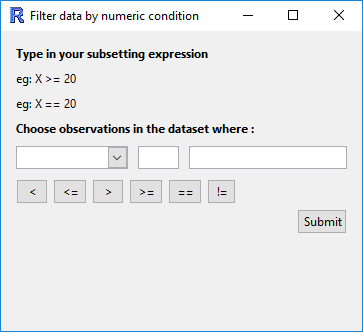
(Filter by) Numeric condition
This allows you to define a condition with which to filter your data.
For example, you could include only the observations of height over 180 cm by
- selecting
heightfrom the drop down menu, - clicking on the
>symbol, and - entering the value
180in the third box.
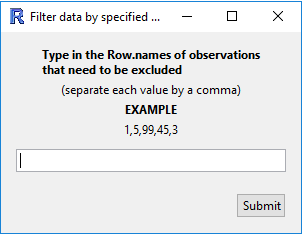
(Filter by) Row number
Exclude a range of row numbers as follows:
- Entering 101:1000 (and then Submit) will exclude all rows from 101 to 1000
-
Similarly, 1, 5, 99, 101:1000 will exclude rows 1, 5, 99, and everything from 101 to 1000
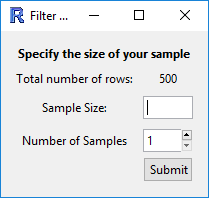
(Filter by) Randomly
Essentially, this allows you to perform bootstrap randomisation manually. The current behaviour is this:
- "Sample Size", n, is the number of observations to draw for each sample,
- "Number of Samples", m, is the number of samples to create in the new data set.
- The output will be a data set with n x m rows, which must be smaller than the total number of rows in the data set.
-
The observations are drawn randomly without replacement from the data set.
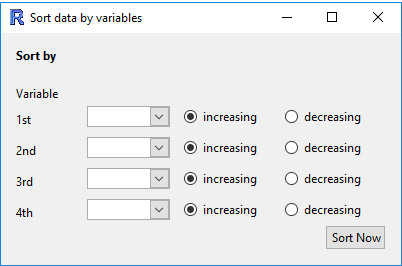
Sort data by variables
Sort the rows of the data by one or more variables
- The ordering will be nested, so that the data is first ordered by "Variable 1", and then "Variable 2", etc.
- For categorical variables, the ordering will be based on the order of the variable (by default, this will be alphabetical unless manually changed in "Manipulate Variables" > "Categorical Variables" > "Reorder Levels").
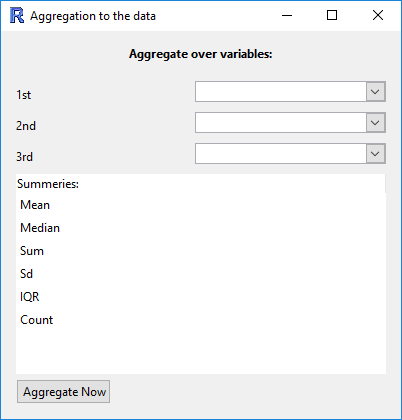
Aggregate data
This function essentially allows you to obtain "summaries" of all of the numeric variables in the data set for combinations of categorical variables.
- Variables: if only one variable is specified, the new data set will have one row for each level of the variable.
If two (or more) are specified, then there will be one row for each combination.
For example, the categorical variables
gender = {male, female}andethnicity = {white, black, asian, other}will result in a data set with 2x4 rows. - Summaries: each row will have the chosen summaries given for each numeric variable in the data set.
For example, if the data set has the variables
gender (cat)andheight (num), and if the user selectsMeanandSd, then the new data set will have the columnsgender,height.Meanandheight.Sd. In the rows, the values will be for that combination of categorical variables; the row forgender = femalewill have the mean height of the females, and the standard deviation of height for the females. A visual example of this would be do dragheightinto the Variable 1 slot, andgenderinto the Variable 2 slot. Clicking on "Get Summary" would provide the same information. The advantage of using Aggregate is that the summaries are calculated for every numeric variable in the data set, not just one of them.
Stack variables
Convert from table form (rows corresponding to subjects) to long form (rows corresponding to observations).
In many cases, the data may be in tabular form, in which multiple observations are made but placed in different columns.
An example of this may be a study of blood pressure on patients using several medications. The columns of this data set may be:
patient.id, gender, drug, Week1, Week2, Week3. Here, each patient has their own row in the data set, but each row contains three observations of blood pressure.
| patient.id | gender | drug | Week1 | Week2 | Week 3 |
|---|---|---|---|---|---|
| 1 | male | A | 130 | 125 | 120 |
| 2 | male | B | 140 | 130 | 110 |
| 3 | female | A | 120 | 119 | 116 |
We may want to convert to long form, where we have each observation in a new row, and use a categorical variable to differentiate the weeks.
In this case, we would select Week1, Week2, and Week3 as the variables in the list. The new data set will have the columns
patient.id, gender, drug, Stack.variable ("Week"), and stack.value ("blood pressure").
| patient.id | gender | drug | stack.variable | stack.value |
|---|---|---|---|---|
| 1 | male | A | Week1 | 130 |
| 1 | male | A | Week2 | 125 |
| 1 | male | A | Week3 | 120 |
| 2 | male | B | Week1 | 140 |
| 2 | male | B | Week2 | 130 |
| 2 | male | B | Week3 | 110 |
| 3 | female | A | Week1 | 120 |
| 3 | female | A | Week2 | 119 |
| 3 | female | A | Week3 | 116 |
Of course, you can rename the variables as appropriate using "Manipulate Variables" > "Rename Variables".
Dataset operations

It offers three types of tools for the users to modify their dataset:
• Reshape dataset
• Separate column
• Unite columns
Reshape dataset
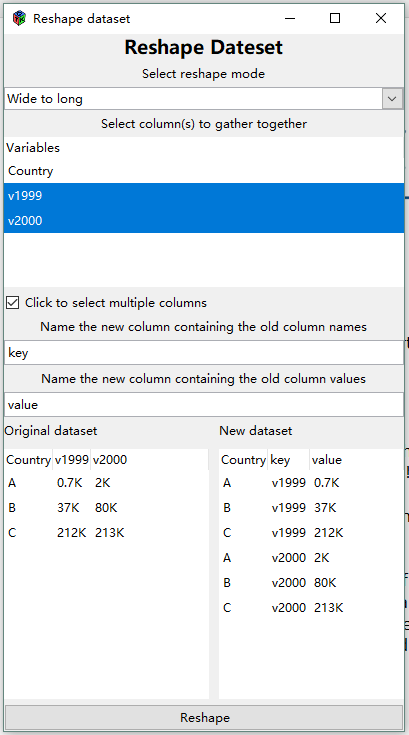
(Reshape) Wide to long
This allows you to select a column or multiple columns from your dataset.
- One new column (default name
key) is populated by the column name(s) of the selected column(s) - The other new column (default name
value) will contain the column value from the selected columns. - The selected column(s) will be removed and two new columns will be added to the dataset.
- A preview panel shows what the new dataset will look like.
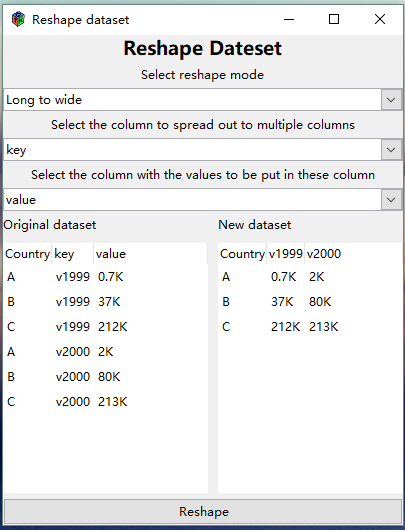
(Reshape) Long to wide
You can select a column to spread out into multiple columns (the column is named key in the example).
It will use the column values of the selected column as a set of names for new columns.
You then select another column with corresponding values to be put into the new columns (the column is named value in the example).
Separate column into ...
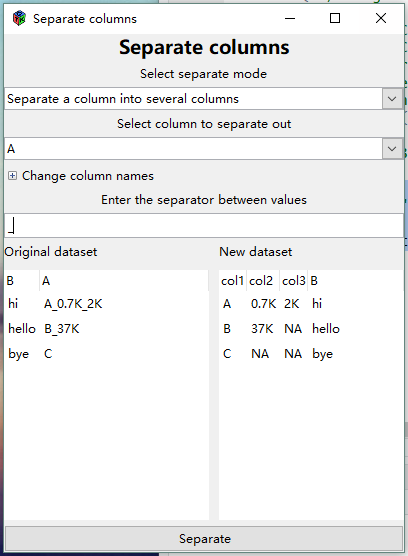
Separate a column into several columns
Allows you to separate a column into several columns using a user-defined separator.
- It will separate at every instance of the separator until no further separators are found
If no separator is found, the additional columns formed will contain NAs.
In the example on to the right, we have asked to separate column A using an underscore (“_”) as a separator.
Because only column A is being separated, column B (or any other columns) is left unchanged in the resulting new dataset
The maximum number of fields in column A after separation is 3 ("A_0.7K_2K") so column A in the original dataset is being replaced by 3 columns with default column names (Col1, etc).
- Expanding Change column names (click the "+") allows you to change the default column names to something else.
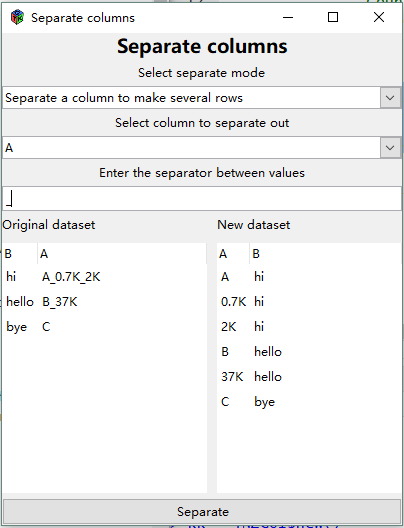
Separate a column into several rows
Instead of forming more columns this version of Separate keeps the same number of columns, with the same names, but writes more rows.
Using the same data as in the example above, the entry "A_0.7K_2K" in column A in the original dataset results in 3 rows in column A in the new dataset.
- The corresponding entries in any other columns (e.g. column B in the example) are duplicated.
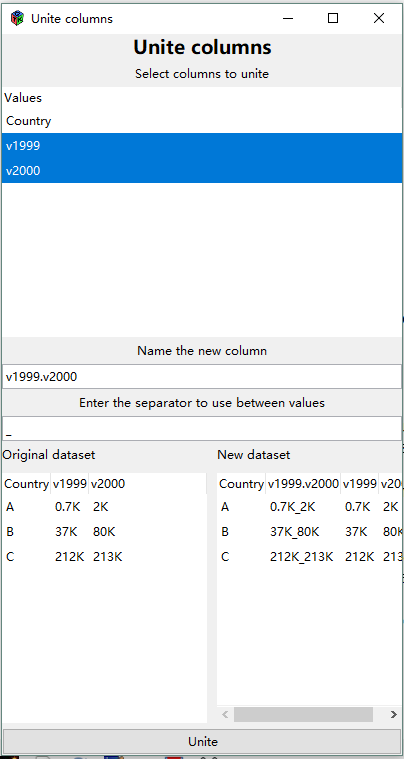
Unite columns
Allows you to select multiple columns and “unite” them using a defined separator (defaults to “_”). The united column name will be the combination of the selected columns with a “.” in between.
In this example, column “v1999” and column “v2000” are united by “”. The new column name is “v1999.v2000”._
- It is allowable to have no separator. Just clear the Enter the separator field (delete the “_”)
Merge/Join datasets
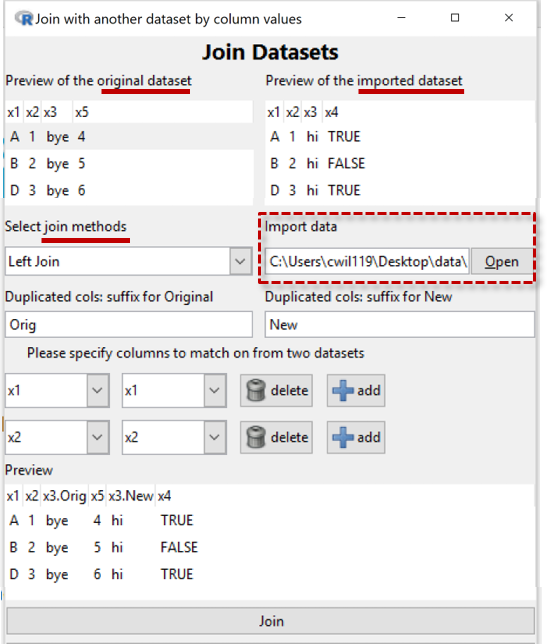
Join Datasets
This "joins", or brings together, information in two data sets: the current dataset in iNZight and a newly imported dataset (read in using the Import data facility) shown at the mid-right.
Left Join: The most important joining method is called a Left Join, the main purpose of which is to add new variables to the original dataset by extracting the information from the new dataset.
Matching rows: (Not yet fully implemented in Lite.) The main problem is to identify what pieces of information belong together. The most straightforward case occurs where there is a variable in the original dataset which is a unique identifier. If that variable is also in the imported dataset (even if under a different name) we can use it to match up the data which belongs to the same unit/entity.
To partially automate the process, iNZight looks for variables with the same name in both datasets (originally x1, x2, and x3 in the Example to the right) and offers those for determining matches.
In the Example, we have rejected x3 using the delete button beside it and so have effectively told the program that it is units with the same values of both x1 and x2 that belong together.
- The Preview panel shows us the effects of our choices
Click the Join button at the bottom once you are happy with the way the data is being joined.
The details of how the data is treated depend on the type of Join and we will document that after finishing describing the Example.
In the Example, x4 is a new variable so that has been added to the preview-dataset. A complication is x3 which is in both datasets but with different values for the "same" units. So the program has decided to make two variables, one for the x3 values from the original dataset and one for the x3 values from the new dataset.
Types of Join
Left Join
- The joined dataset has rows corresponding to all of the rows in the original dataset and all of its columns.
- Rows of the new dataset that do not have a match in the original dataset are not used.
- The joined dataset also has the columns from the new dataset that were not used for matching.
- Rows in the original that have no match in the newly imported dataset get
NAs for the additional columns - Warning: Rows from the original dataset that have more than one match in the new dataset generate multiple rows in the joined dataset (which invalidates many simple analyses). For example, if there are 3 matches then the original (single) row will be replaced by 3 rows. The cell-values for the additional columns will be obtained from the new data set and the values for the original columns from repeating the original cell values.
How other joins differ from the Left Join
-
Inner Join: Only use rows corresponding to matches between the two datasets
- Full Join (Outer Join): Also use all the non-matching rows from both data sets
[Right Join: iNZight does not have this. Just import the datasets in the reverse order and use a left join.]
The following are just used to filter data. No columns are added to the join from the new dataset.
-
Semi Join: Use only rows in the original which have a match in the new
- Anti Join: Use only rows in the original which have no match in the new
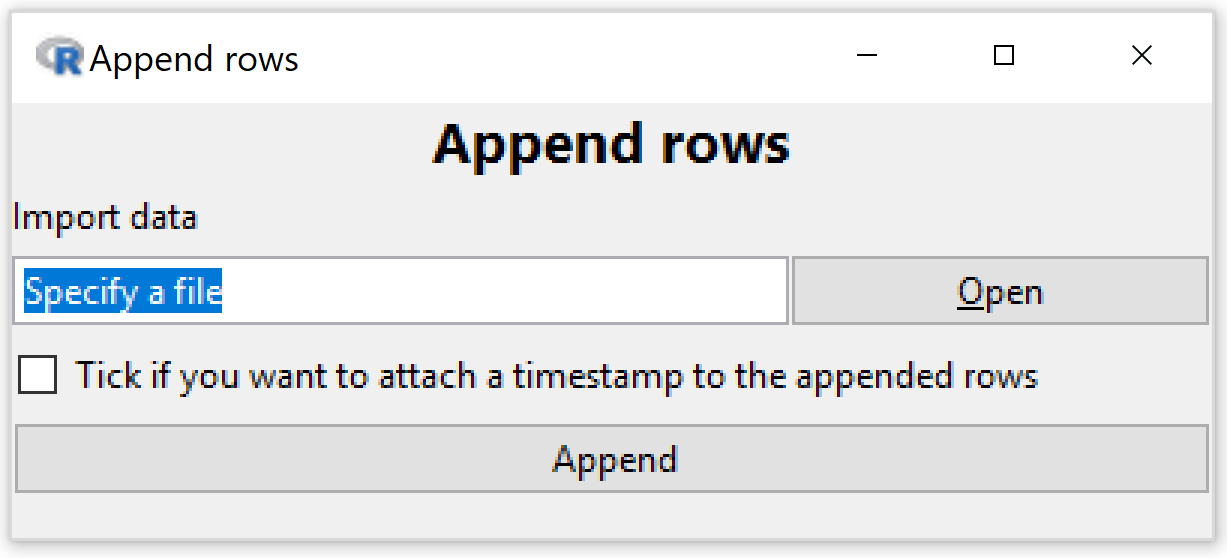
Append rows
Adds to the bottom of the original dataset rows from a newly imported dataset (imported using the Import facility provided).
- The column names from both datasets are matched so the correct data goes into the correct columns
- Columns that appear in one dataset and not the other will appear in the result
-
An error will be reported and not appending will be possible if two column names match but their types (e.g. numeric or categorical) do not match
- If the Tick-box option is selected a timestamp variable called When_Added will be added to the dataset recording when the new observations were added
- If there is already a variable called When_Added present in the original data (must be of type date-time, "(t)" in View Variables) the new timestamps will be appended to that existing variable
Where data is periodically being added to a dataset, this facility can be used to keep track of when each row was added -- thus facilitating analyses of the data as it was up until any particular time point
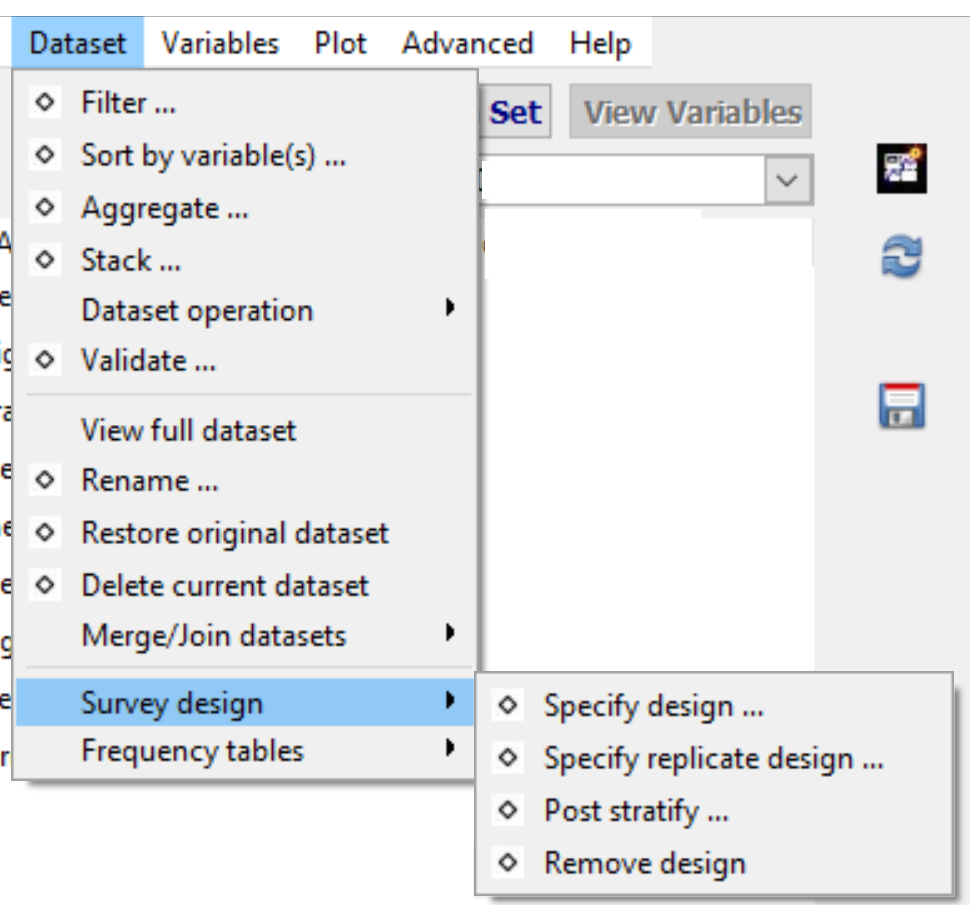
Survey design
• About survey data
• Specify design ...
• Specify replicate design ...
• Post stratify ... (or rake or calibrate)
• Remove design ...
About survey data
It is important that specialist methods be applied when analyzing data obtained using complex survey designs. Failure to do so typically leads biased estimates and incorrect standard errors, confidence intervals and p-values.
When a survey design has been defined almost all relevant parts of iNZight will apply analysis and graphics methods appropriate for data obtained using this survey design by applying functions in R's survey package.
Important difference for Get Summary. Whereas, generally, iNZight's Get Summary provides summary information about the dataset itself, when a survey design is specified Get Summary provides estimates of population quantities -- clearly labeled as such. (Raw summaries of survey data are often meaningless because of unequal probabilities of selection.)
Regular statistical software analyses data as if the data were collected using simple random sampling. Many surveys, however, are conducted using more complicated sampling methods. Not only is it often nearly impossible to implement simple random sampling, more complex methods are more efficient both financially and statistically. These methods use some or all of stratified sampling, cluster sampling and unequal sampling rates whereby some parts of a population are sampled more heavily (i.e. with higher probabilities of selection) than others parts. These sampling features have to be allowed for in the analysis. While sometimes it may be possible to get reasonably accurate results using non-survey software, there is no practical way to know beforehand how far wrong the results from non-survey software will be.
- See Brief introduction to survey analysis ideas
- For an in-depth account, see "iNZight and Sample Surveys" by Richard Arnold.
Survey designs are typically specified to analysis programs either by specifying a survey design in terms of weighting, strata and clustering variables etc in the data set, or by selecting a set of variables in the dataset containing so-called replicate weights. Post-stratification/raking/calibration facilitate using additional population information (external to the survey data) to improve survey estimates. This is done after a survey design has been specified (by either method).
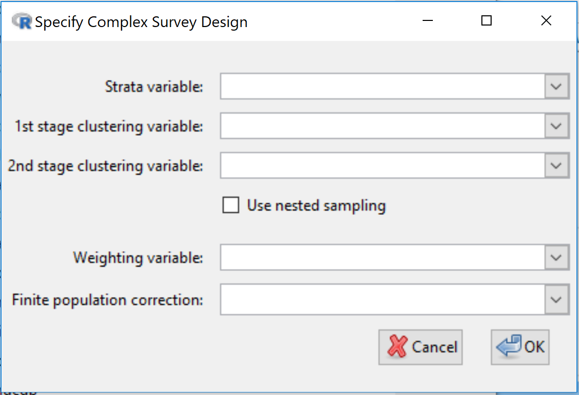
Specify design
Specifying a survey design in terms of weighting, strata and clustering variables etc.
iNZight’s survey methods cater for simple random sampling, stratified random sampling (random sampling within each population stratum), cluster sampling and multistage cluster sampling, and complex designs involving cluster sampling within population strata.
- Strata variable: If stratified sampling has been performed, use to select the variable that specifies which stratum each observation comes from. (This variable can be either numeric or categorical.)
- 1st stage clustering variable: If cluster sampling has been performed, use to select the 1st-stage clustering variable; this specifies which 1st-stage cluster each observation comes from. (Clustering variables can also be either numeric or categorical.)
- 2nd stage clustering variable: If two or more stages of cluster sampling have been performed, use to select the 2nd-stage clustering variable (specifies which 2nd-stage cluster each observation comes from). Any further levels of cluster sampling (3rd stage, etc., are not used)
- Use nested sampling: Quite often, compilers of survey data "reuse" cluster names from stratum to stratum. Let us take, as an example, a survey in which American states for the starts and counties form the clusters. Sampled counties from Washington State may be given a County value of 1, 2, ... and counties from Arizona may also be given a County value of 1, 2, ... Clearly County 1 from Washington refers to an entirely different county from County 1 from Arizona even though they have the same value of the County variable. -- Click the Use nested sampling check-box if cluster labels are being recycled/reused in the data.
- Weighting variable: If the sampling design used unequal probabilities of selection, use this to select a variable containing the sampling weight (1 over the probability of selection) for each observation. Certain estimates will be wrong if the sampling weights do not add up to the population size, in particular estimated population or subpopulation totals and estimated population or subpopulation sizes. Sampling weights are often adjusted to allow for unit non-response.
- Finite population correction (fpc): Use this when descriptive inferences are wanted about properties of the finite population being sampled and the sample size is an appreciable proportion of the population size (e.g. > 5 or 10%). If stratified sampling has not been used, this variable should contain an estimate of the size of the population being sampled, repeated for every observation. If stratified sampling has been used, the values of this variable should contain an estimate of the size of the population stratum being sampled (differing across strata but constant within each stratum).
As an alternative to using population/stratum sizes, proportions of the total population being sampled can be used.
If one stage cluster sampling has been used (where we take a random sample of clusters, and a census within clusters), the finite-population-correction selection-box should contain an estimate of the total number of clusters (the same on every row, or the same on every row within a stratum).
In two stage clustering we subsample within each selected cluster, and so we need to specify two variables: one for the number of clusters (just as in one stage clustering), and a second for the total number of units available for selection within each cluster (the same value on every row within the cluster). If the number of clusters is stored in a variable called fpc1, and the number of units within a cluster is stored in a variable called fpc2, then type/paste fpc1+fpc2 in the finite population correction field.
For more information on quantities referred to in the dialog box see the documentation of the svydesign function in R's survey package.
Specify replicate design
Because making public factors like cluster membership can make it easier than survey agencies are comfortable with to identify individuals, many agencies do not distribute such information to outsiders. Instead they distribute sets of so-called replicate weights, slightly varying copies of the sampling weights variable that still enable survey analysis programs to make the proper adjustments to analyses of survey data.
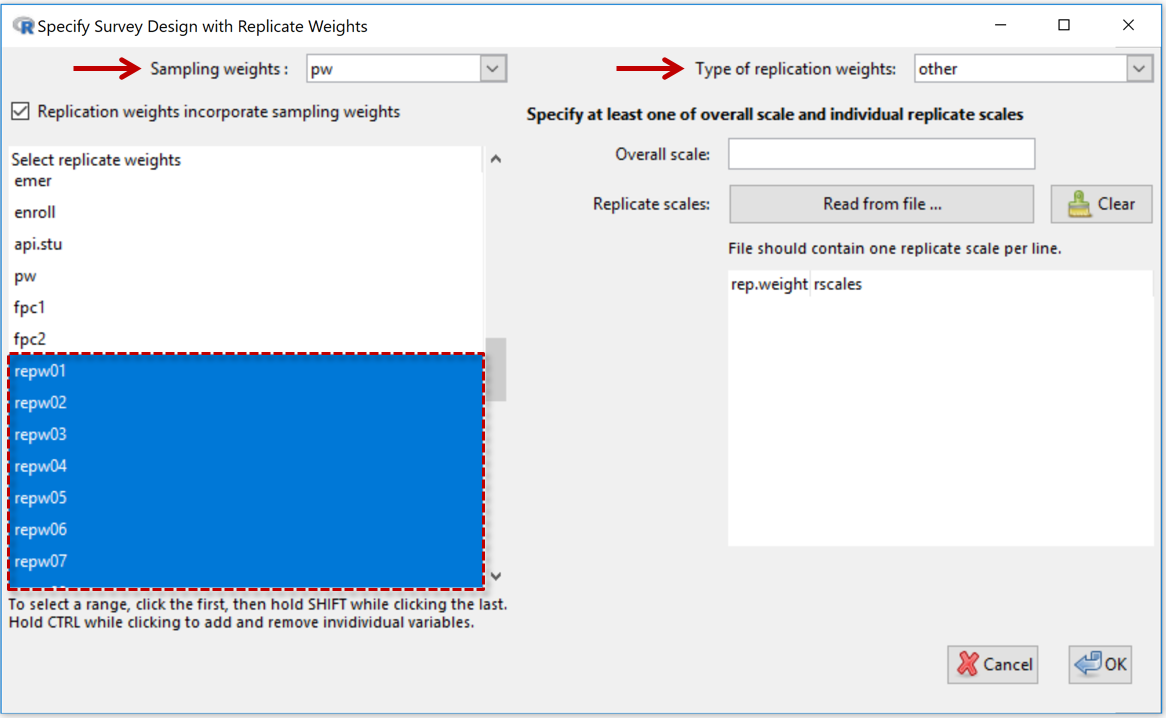
- Sampling Weights: See variable selection box at the top-left
- Replication weights incorporate sampling weights (checkbox): This should be checked if the replicate weights already include the sampling weights (which is usually the case). Uncheck this if the replicate weights are very different in size to the sampling weights.
- Select replicate weights: The large (lower) panel on the left-hand side displays the names of the variables in the dataset. Use to select the replicate-weights variables. In the example shown the replicate-weights variables were called repw01, repw02, repw03, ...
Right-hand panel
- Type of replication weights: Depends on the type of replicate weights the person who compiled the dataset has used. Select from list - BRR, Fay, JK1, JKn, bootstrap, other.
- Overall scales: Only used for Types bootstrap and other.
For more information on quantities referred to above
- see the documentation for the svrepdesign function in R's survey package and also here
- see also the section on replicate weights in "iNZight and Sample Surveys" by Richard Arnold..
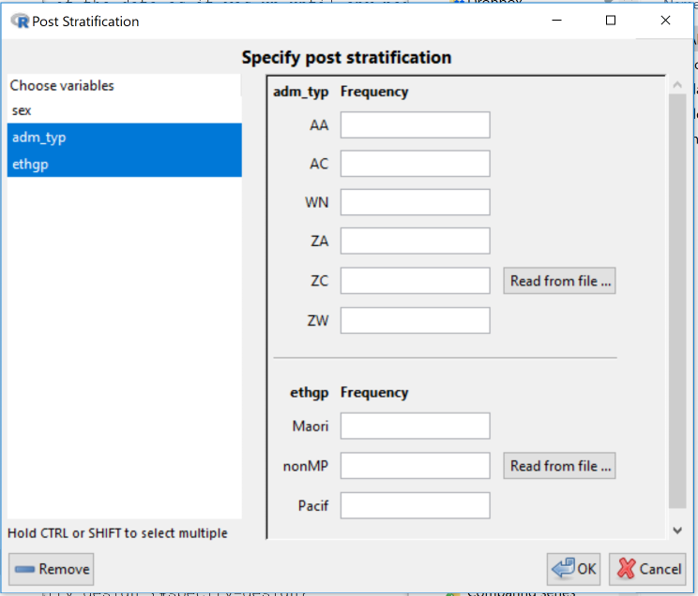
Post stratify
This allows for poststratifying/raking/calibrating a design that has already been defined using either of the methods above above. (Technically the design is updated using the calibrate function in R's survey package.)
This allows a data-analyst to improve estimation by augmenting the information in the survey data by adding information on the whole population where this is available from other sources. Categorical variables in the data set are offered as possible poststratification/raking/calibration candidates. Corresponding population counts can be input by typing or reading from files.
In the example in the screenshot, there are 3 categorical variables in the data set offered as possible candidates and 2 have been selected. The design would then be calibrated using user-supplied information on population counts for the all the categories of both admin_type and ethgp.
This is fine when you only want to use information about single variables, but what if you have population information on the cross-classification (all possible combinations) of admin_type and ethgp, say? Then you would have to create a new variable in the dataset, called say admin_type.ethgp that has all these combinations. This can be done with Variables > Categorical Variables > Combine categorical variables.
Warning: Currently the new variables have to be set up before specifying a survey design. If you only think about it later you will need to use Remove design (next item), set up new variables and then re-specify the design.
For more information on quantities referred to in the dialog box see here ....
Remove design
Discard design information and revert to using standard methods of analysis.
Frequency tables (values plus frequencies data format)
When a frequency column is specified, graphics and summaries respond to a combinations-of-variables-plus-their-frequencies data structure. Only categorical variables are retained.
The expand table option can be used to work with both numeric and categorical variables. The storage and efficiency savings of working with a unique combinations of variables plus frequencies will typically be very much smaller here.
Validate Dataset
Often, we want to validate that the data in a dataset adheres to our expectations about how that data should behave based on external real world-knowledge.
- Validating a data set necessarily requires user-supplied validation rules.
For example, we expect the heights of humans are not negative or someone cannot work for more than 24 hours in a single day.
The validation window gives us the ability to define or import rules, and check whether the data conforms to those rules identifying any exceptions.
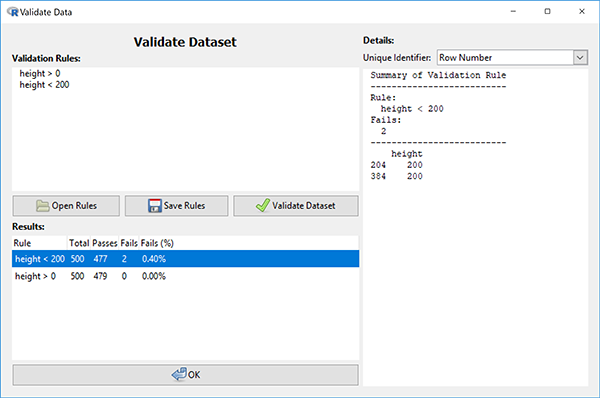
- In the validation window, rules can be typed into the Validation Rules text box in the top left or imported from a text file using the Open Rules button.
Using the first example, the rule to check whether heights are above 0 can be written in this textbox as height > 0 in this text box (given there is a variable named height in our dataset).
- To check all of the rules that have been defined in this textbox, click the Validate Dataset button.
The results of each rule are presented in a table at the bottom of the window and show the number of observations that were checked ("Total"), the number of passes and failures ("Passes" and "Fails" respectively), and the fail percentage ("Fails (%)"). Initially this table is sorted by failure percentage, but you can click on other column headers to order the list in other ways.
- The Unique Identifier selection box at the top right of the validation window allows you to select the name of a variable that contains unique identifiers for the units/cases/rows in the data set.
This is more useful than employing row numbers (the default setting) because unique-identifier values remain unchanged in the data when rows are deleted whereas row numbers will change.
- Double clicking on a row of the results table will generate a detailed breakdown of the results in the Details section on the right-hand side of the window.
This breakdown will provide details about the observations which failed on that particular rule, giving the row numbers (or unique-identifier values if a unique-identifier has been selected) of these observations and the values used to assess the rule.
Validation rules or changes to imported rule files are discarded once the validation window is closed.
- If you would like to store the set of rules you have defined or save any changes to an imported rule file, this can be done using the Save Rules button.
They are saved into a text file on your computer that can be imported again using the "Open Rules" button or viewed using a text editor.
The rules you use to validate the dataset do not need to be simple comparisons between a variable and a static value as in the previous example. More complex rules can be built by performing calculations on the variables, e.g. weight / height^2 < 50 will verify that each observation's body mass index is below 50. The values of each variable contained in the calculation as well as the end result are provided in the detailed breakdown.
- Instead of comparisons between a variable/calculation and a static value, we can compare against another variable or a calculation based on the data.
For example, to check that the income of an individual (contained in variable Income) is no more than 1000 times their number of hours per week (contained in variable Hours), we can use the following rule: Income <= Hours * 1000. This will calculate a different value to compare income against for each observation.
For more information on what is possible using validation rules, the vignettes and help files of the underlying R package (validate) might be useful: Introduction to Validate vignette and Validate package (in particular, the syntax section of the reference manual).
Restore Dataset
Restores the data set to the way it was when it was initially imported.
